 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetraining DistilBERT for a Voice Shopping Assistant by Using Universal Dependencies
Paper and Code
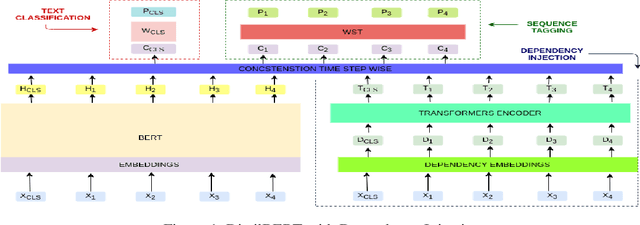

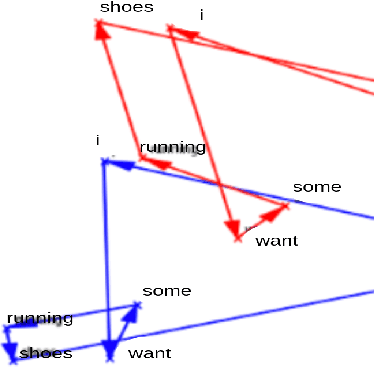
In this work, we retrained the distilled BERT language model for Walmart's voice shopping assistant on retail domain-specific data. We also injected universal syntactic dependencies to improve the performance of the model further. The Natural Language Understanding (NLU) components of the voice assistants available today are heavily dependent on language models for various tasks. The generic language models such as BERT and RoBERTa are useful for domain-independent assistants but have limitations when they cater to a specific domain. For example, in the shopping domain, the token 'horizon' means a brand instead of its literal meaning. Generic models are not able to capture such subtleties. So, in this work, we retrained a distilled version of the BERT language model on retail domain-specific data for Walmart's voice shopping assistant. We also included universal dependency-based features in the retraining process further to improve the performance of the model on downstream tasks. We evaluated the performance of the retrained language model on four downstream tasks, including intent-entity detection, sentiment analysis, voice title shortening and proactive intent suggestion. We observed an increase in the performance of all the downstream tasks of up to 1.31% on average.