 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotating Hate and Offenses on Social Media
Paper and Code
Apr 06, 2021
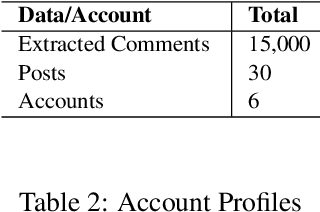
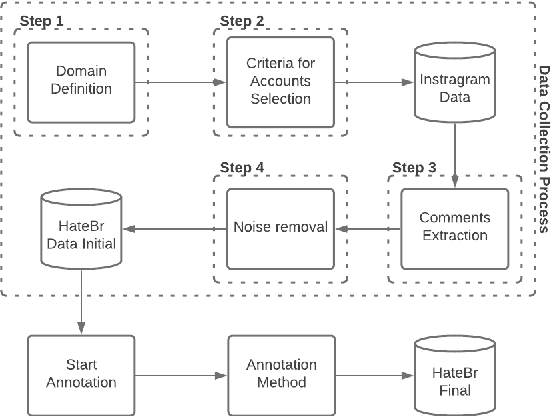
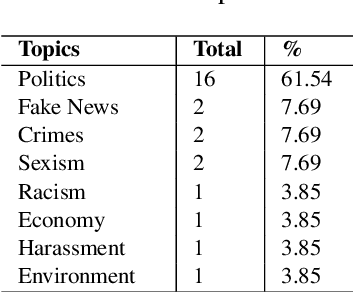
This paper describes a corpus annotation process to support the identification of hate speech and offensive language in social media. In addition, we provide the first robust corpus this kind for the Brazilian Portuguese language. The corpus was collected from Instagram pages of political personalities and manually annotated, being composed by 7,000 documents annotated according to three different layers: a binary classification (offensive versus non-offensive language), the level of offense (highly offensive, moderately offensive and slightly offensive messages), and the identification regarding the target of the discriminatory content (xenophobia, racism, homophobia, sexism, religion intolerance, partyism, apology to the dictatorship, antisemitism and fat phobia). Each comment was annotated by three different annotators, which achieved high inter-annotator agreement. The proposed annotation approach is also language and domain independent, nevertheless, it was currently applied for Brazilian Portuguese.