 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision Transformers Learn without Natural Images?
Paper and Code
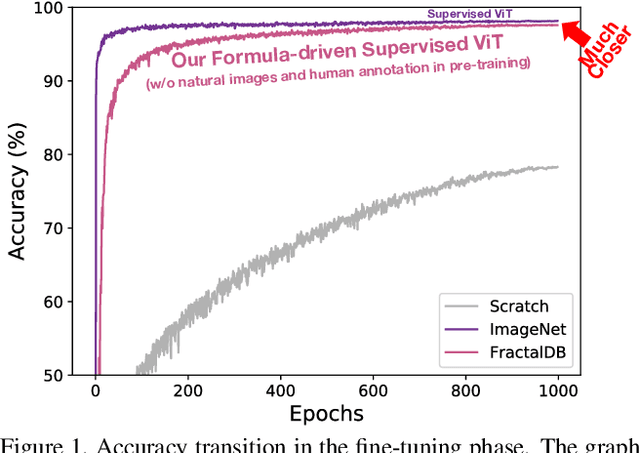
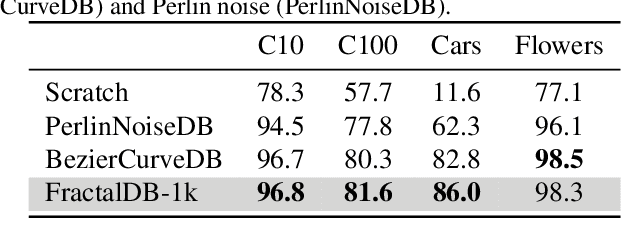
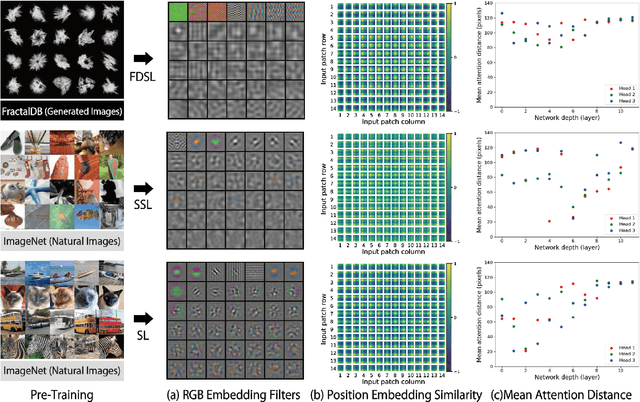
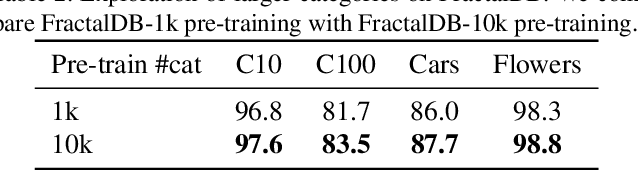
Can we complete pre-training of Vision Transformers (ViT) without natural images and human-annotated labels? Although a pre-trained ViT seems to heavily rely on a large-scale dataset and human-annotated labels, recent large-scale datasets contain several problems in terms of privacy violations, inadequate fairness protection, and labor-intensive annotation. In the present paper, we pre-train ViT without any image collections and annotation labor. We experimentally verify that our proposed framework partially outperforms sophisticated Self-Supervised Learning (SSL) methods like SimCLRv2 and MoCov2 without using any natural images in the pre-training phase. Moreover, although the ViT pre-trained without natural images produces some different visualizations from ImageNet pre-trained ViT, it can interpret natural image datasets to a large extent. For example, the performance rates on the CIFAR-10 dataset are as follows: our proposal 97.6 vs. SimCLRv2 97.4 vs. ImageNet 98.0.