 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Your Heart Speak in its Mother Tongue: Multilingual Captioning of Cardiac Signals
Paper and Code
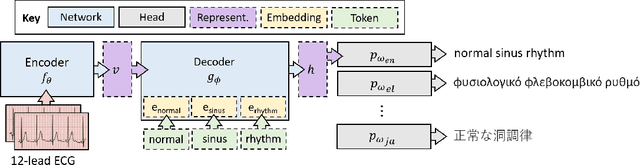
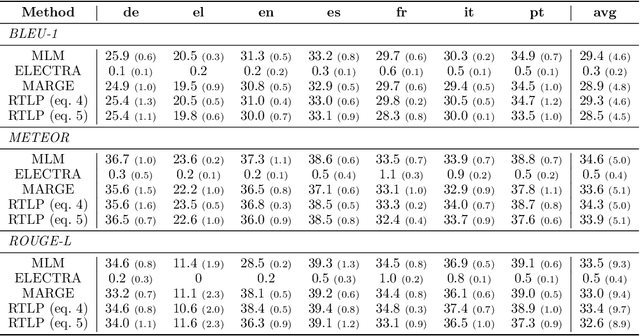
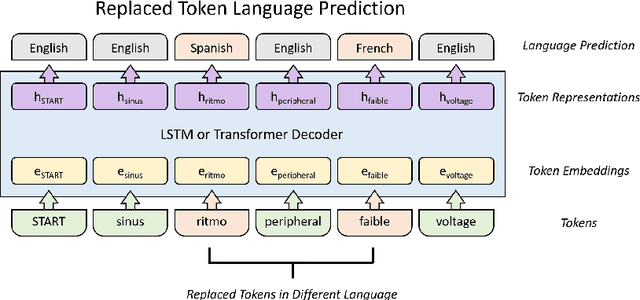

Cardiac signals, such as the electrocardiogram, convey a significant amount of information about the health status of a patient which is typically summarized by a clinician in the form of a clinical report, a cumbersome process that is prone to errors. To streamline this routine process, we propose a deep neural network capable of captioning cardiac signals; it receives a cardiac signal as input and generates a clinical report as output. We extend this further to generate multilingual reports. To that end, we create and make publicly available a multilingual clinical report dataset. In the absence of sufficient labelled data, deep neural networks can benefit from a warm-start, or pre-training, procedure in which parameters are first learned in an arbitrary task. We propose such a task in the form of discriminative multilingual pre-training where tokens from clinical reports are randomly replaced with those from other languages and the network is tasked with predicting the language of all tokens. We show that our method performs on par with state-of-the-art pre-training methods such as MLM, ELECTRA, and MARGE, while simultaneously generating diverse and plausible clinical reports. We also demonstrate that multilingual models can outperform their monolingual counterparts, informally terming this beneficial phenomenon as the blessing of multilinguality.