 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe impact of using biased performance metrics on software defect prediction research
Paper and Code
Mar 24, 2021
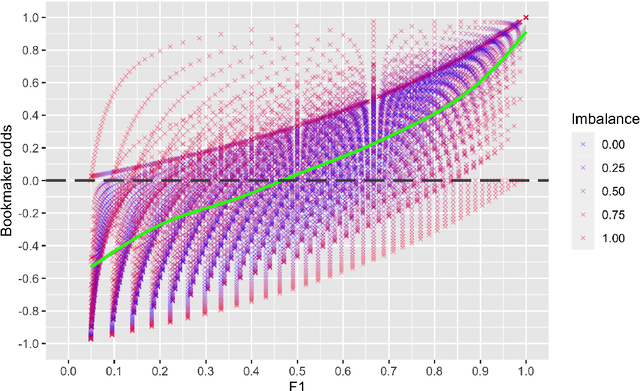
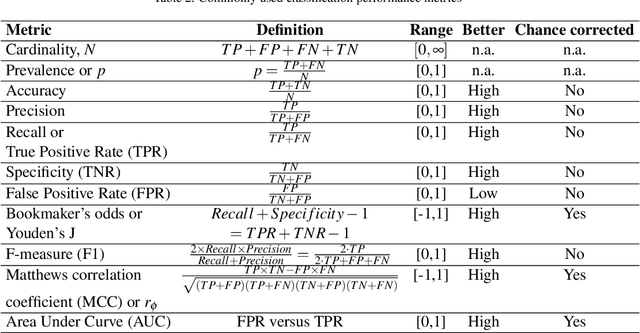
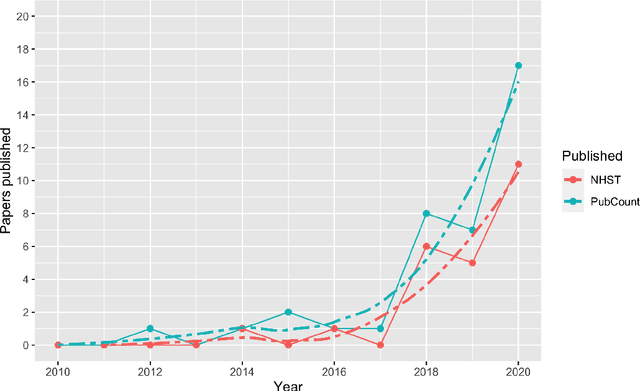
Context: Software engineering researchers have undertaken many experiments investigating the potential of software defect prediction algorithms. Unfortunately, some widely used performance metrics are known to be problematic, most notably F1, but nevertheless F1 is widely used. Objective: To investigate the potential impact of using F1 on the validity of this large body of research. Method: We undertook a systematic review to locate relevant experiments and then extract all pairwise comparisons of defect prediction performance using F1 and the un-biased Matthews correlation coefficient (MCC). Results: We found a total of 38 primary studies. These contain 12,471 pairs of results. Of these, 21.95% changed direction when the MCC metric is used instead of the biased F1 metric. Unfortunately, we also found evidence suggesting that F1 remains widely used in software defect prediction research. Conclusions: We reiterate the concerns of statisticians that the F1 is a problematic metric outside of an information retrieval context, since we are concerned about both classes (defect-prone and not defect-prone units). This inappropriate usage has led to a substantial number (more than one fifth) of erroneous (in terms of direction) results. Therefore we urge researchers to (i) use an unbiased metric and (ii) publish detailed results including confusion matrices such that alternative analyses become possible.