 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Deep Learning Using Volunteer Computing-Like Paradigm
Paper and Code
Apr 02, 2021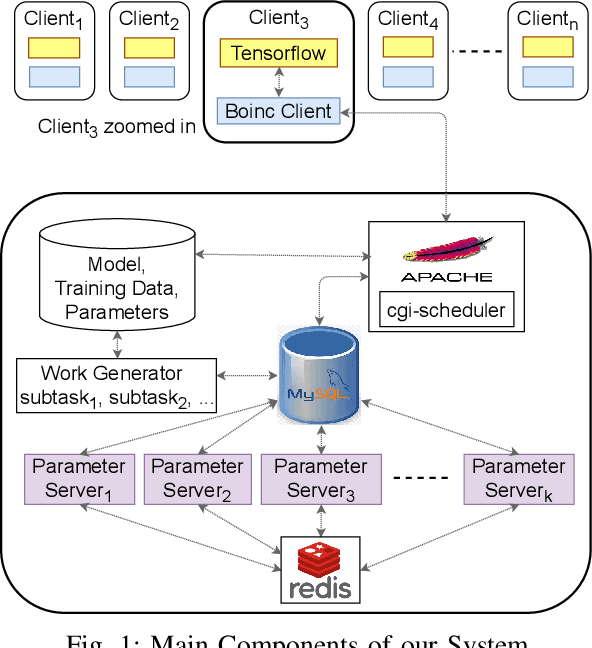
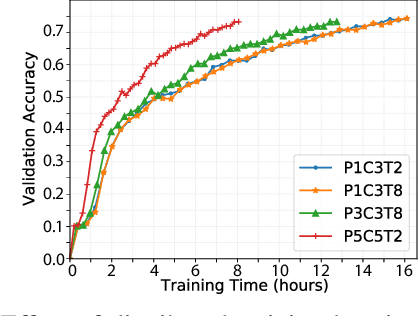
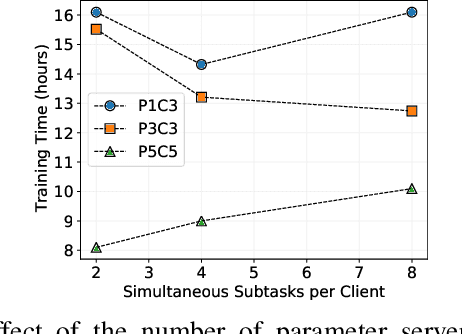
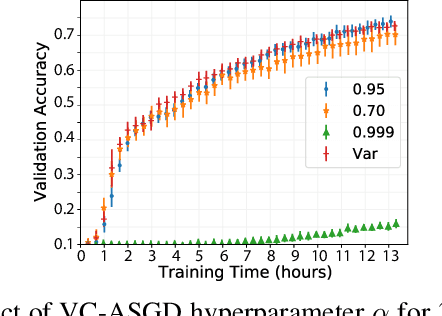
Use of Deep Learning (DL) in commercial applications such as image classification, sentiment analysis and speech recognition is increasing. When training DL models with large number of parameters and/or large datasets, cost and speed of training can become prohibitive. Distributed DL training solutions that split a training job into subtasks and execute them over multiple nodes can decrease training time. However, the cost of current solutions, built predominantly for cluster computing systems, can still be an issue. In contrast to cluster computing systems, Volunteer Computing (VC) systems can lower the cost of computing, but applications running on VC systems have to handle fault tolerance, variable network latency and heterogeneity of compute nodes, and the current solutions are not designed to do so. We design a distributed solution that can run DL training on a VC system by using a data parallel approach. We implement a novel asynchronous SGD scheme called VC-ASGD suited for VC systems. In contrast to traditional VC systems that lower cost by using untrustworthy volunteer devices, we lower cost by leveraging preemptible computing instances on commercial cloud platforms. By using preemptible instances that require applications to be fault tolerant, we lower cost by 70-90% and improve data security.