 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVDSM: Unsupervised Video Disentanglement with State-Space Modeling and Deep Mixtures of Experts
Paper and Code

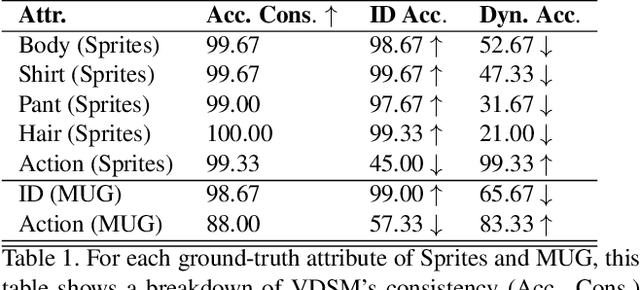
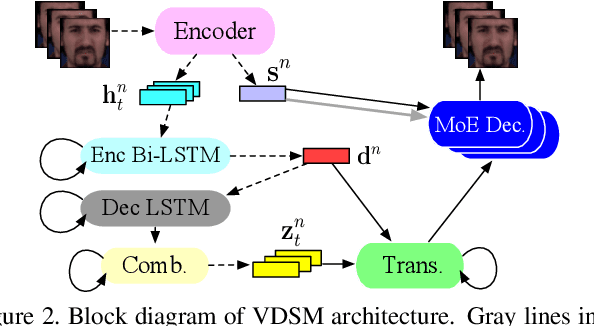
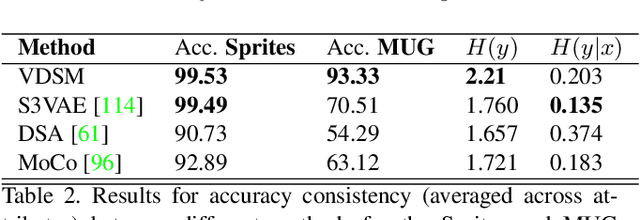
Disentangled representations support a range of downstream tasks including causal reasoning, generative modeling, and fair machine learning. Unfortunately, disentanglement has been shown to be impossible without the incorporation of supervision or inductive bias. Given that supervision is often expensive or infeasible to acquire, we choose to incorporate structural inductive bias and present an unsupervised, deep State-Space-Model for Video Disentanglement (VDSM). The model disentangles latent time-varying and dynamic factors via the incorporation of hierarchical structure with a dynamic prior and a Mixture of Experts decoder. VDSM learns separate disentangled representations for the identity of the object or person in the video, and for the action being performed. We evaluate VDSM across a range of qualitative and quantitative tasks including identity and dynamics transfer, sequence generation, Fr\'echet Inception Distance, and factor classification. VDSM provides state-of-the-art performance and exceeds adversarial methods, even when the methods use additional supervision.