 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast Adaptive Tissue Classification by Alternating Segmentation and Synthesis
Paper and Code
Mar 04, 2021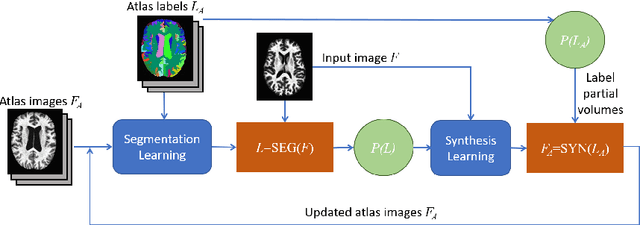
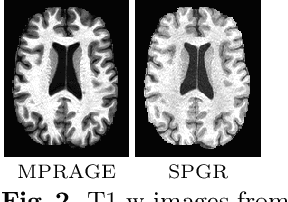
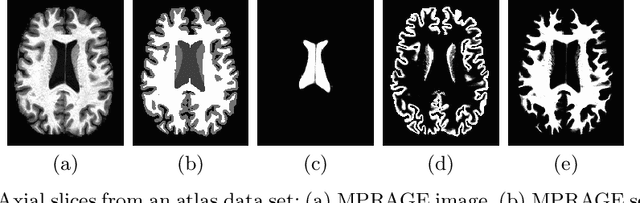
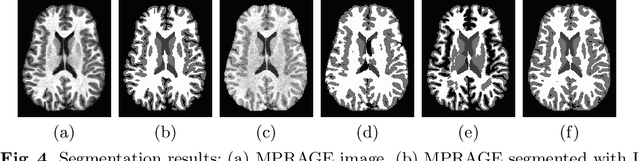
Deep learning approaches to the segmentation of magnetic resonance images have shown significant promise in automating the quantitative analysis of brain images. However, a continuing challenge has been its sensitivity to the variability of acquisition protocols. Attempting to segment images that have different contrast properties from those within the training data generally leads to significantly reduced performance. Furthermore, heterogeneous data sets cannot be easily evaluated because the quantitative variation due to acquisition differences often dwarfs the variation due to the biological differences that one seeks to measure. In this work, we describe an approach using alternating segmentation and synthesis steps that adapts the contrast properties of the training data to the input image. This allows input images that do not resemble the training data to be more consistently segmented. A notable advantage of this approach is that only a single example of the acquisition protocol is required to adapt to its contrast properties. We demonstrate the efficacy of our approaching using brain images from a set of human subjects scanned with two different T1-weighted volumetric protocols.