 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Edge Machine Learning Inference Bottlenecks: An Empirical Study on Accelerating Google Edge Models
Paper and Code
Mar 01, 2021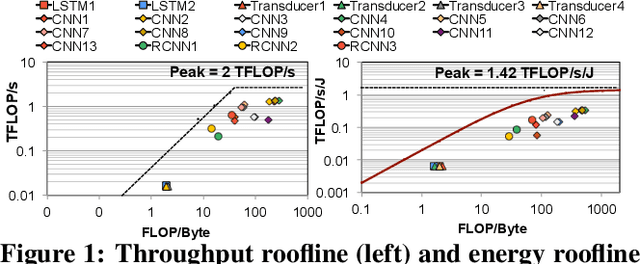
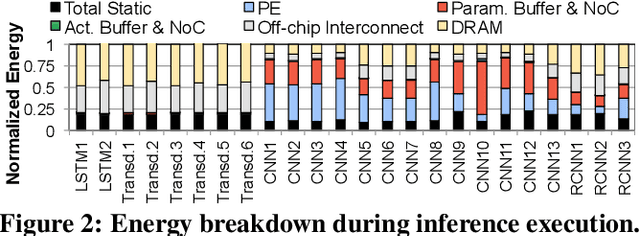
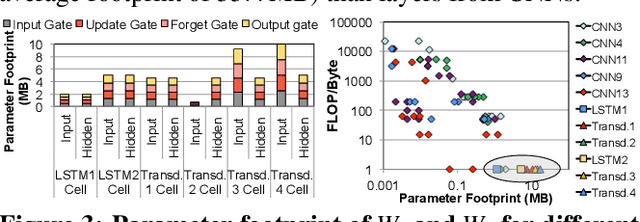
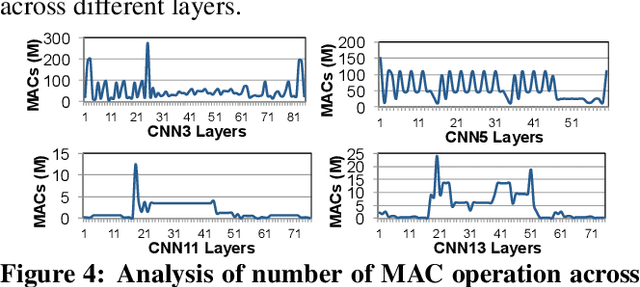
As the need for edge computing grows, many modern consumer devices now contain edge machine learning (ML) accelerators that can compute a wide range of neural network (NN) models while still fitting within tight resource constraints. We analyze a commercial Edge TPU using 24 Google edge NN models (including CNNs, LSTMs, transducers, and RCNNs), and find that the accelerator suffers from three shortcomings, in terms of computational throughput, energy efficiency, and memory access handling. We comprehensively study the characteristics of each NN layer in all of the Google edge models, and find that these shortcomings arise from the one-size-fits-all approach of the accelerator, as there is a high amount of heterogeneity in key layer characteristics both across different models and across different layers in the same model. We propose a new acceleration framework called Mensa. Mensa incorporates multiple heterogeneous ML edge accelerators (including both on-chip and near-data accelerators), each of which caters to the characteristics of a particular subset of models. At runtime, Mensa schedules each layer to run on the best-suited accelerator, accounting for both efficiency and inter-layer dependencies. As we analyze the Google edge NN models, we discover that all of the layers naturally group into a small number of clusters, which allows us to design an efficient implementation of Mensa for these models with only three specialized accelerators. Averaged across all 24 Google edge models, Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Edge TPU, and by 2.4x and 4.3x over Eyeriss v2, a state-of-the-art accelerator.