 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDS-MEMBED: Multi-sense embeddings based on enhanced distributional semantic structures via a graph walk over word senses
Paper and Code
Feb 27, 2021


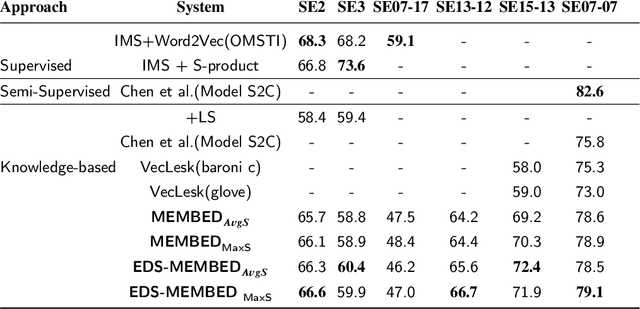
Several language applications often require word semantics as a core part of their processing pipeline, either as precise meaning inference or semantic similarity. Multi-sense embeddings (M-SE) can be exploited for this important requirement. M-SE seeks to represent each word by their distinct senses in order to resolve the conflation of meanings of words as used in different contexts. Previous works usually approach this task by training a model on a large corpus and often ignore the effect and usefulness of the semantic relations offered by lexical resources. However, even with large training data, coverage of all possible word senses is still an issue. In addition, a considerable percentage of contextual semantic knowledge are never learned because a huge amount of possible distributional semantic structures are never explored. In this paper, we leverage the rich semantic structures in WordNet using a graph-theoretic walk technique over word senses to enhance the quality of multi-sense embeddings. This algorithm composes enriched texts from the original texts. Furthermore, we derive new distributional semantic similarity measures for M-SE from prior ones. We adapt these measures to word sense disambiguation (WSD) aspect of our experiment. We report evaluation results on 11 benchmark datasets involving WSD and Word Similarity tasks and show that our method for enhancing distributional semantic structures improves embeddings quality on the baselines. Despite the small training data, it achieves state-of-the-art performance on some of the datasets.