 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Part-of-speech Tagging with Syntactic Information for Vietnamese and Chinese
Paper and Code
Feb 24, 2021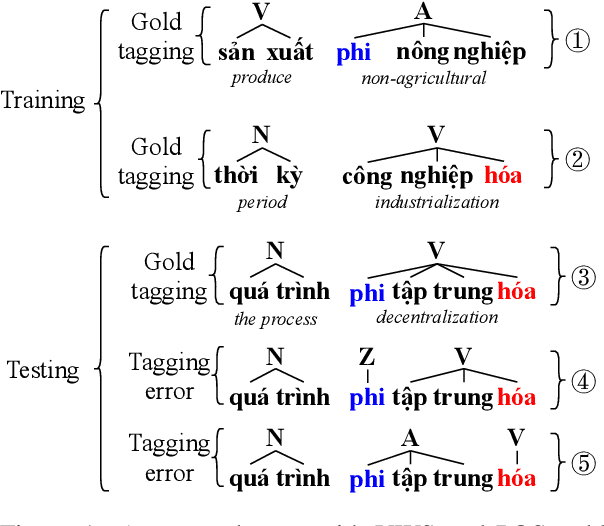
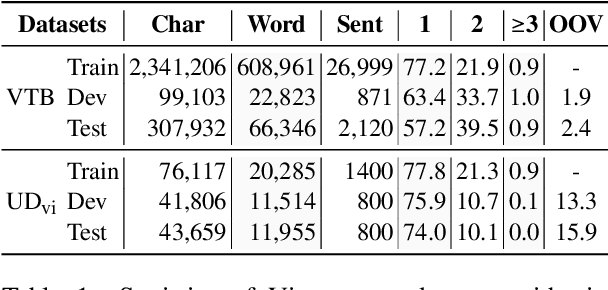
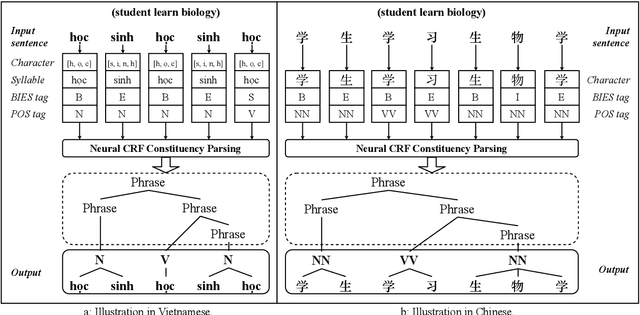
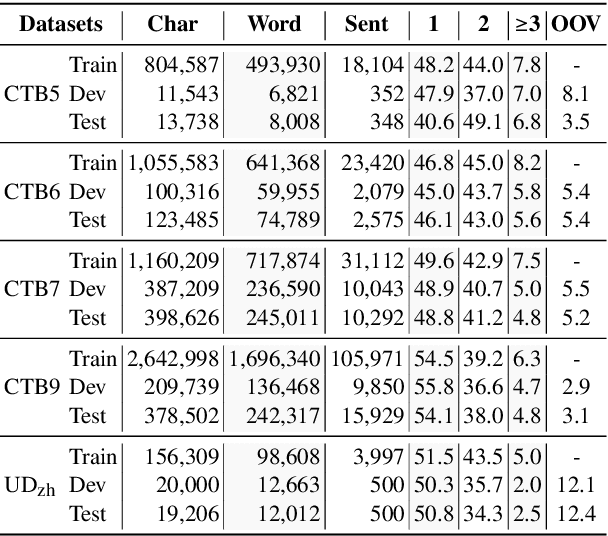
Word segmentation and part-of-speech tagging are two critical preliminary steps for downstream tasks in Vietnamese natural language processing. In reality, people tend to consider also the phrase boundary when performing word segmentation and part of speech tagging rather than solely process word by word from left to right. In this paper, we implement this idea to improve word segmentation and part of speech tagging the Vietnamese language by employing a simplified constituency parser. Our neural model for joint word segmentation and part-of-speech tagging has the architecture of the syllable-based CRF constituency parser. To reduce the complexity of parsing, we replace all constituent labels with a single label indicating for phrases. This model can be augmented with predicted word boundary and part-of-speech tags by other tools. Because Vietnamese and Chinese have some similar linguistic phenomena, we evaluated the proposed model and its augmented versions on three Vietnamese benchmark datasets and six Chinese benchmark datasets. Our experimental results show that the proposed model achieves higher performances than previous works for both languages.