 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard-Attention for Scalable Image Classification
Paper and Code
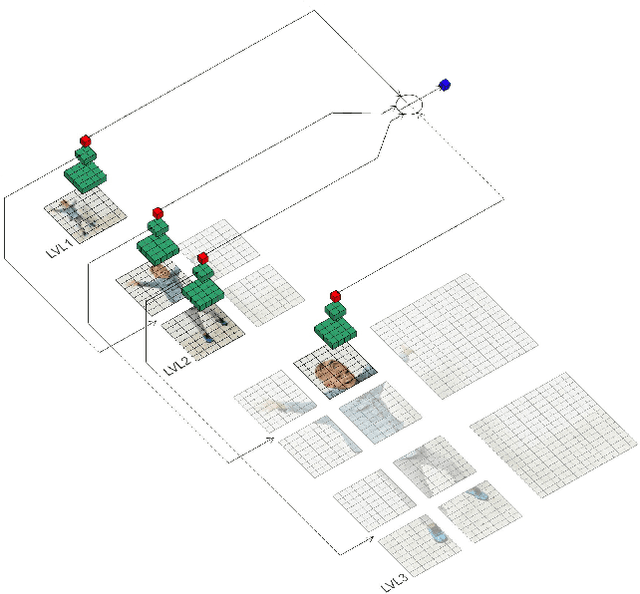
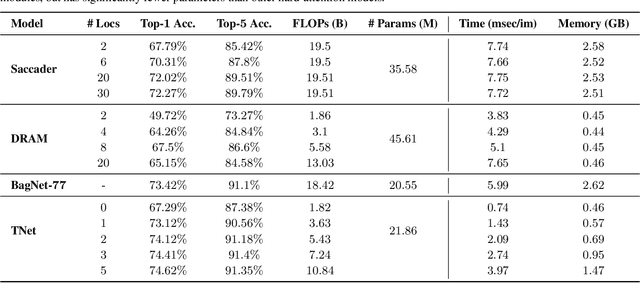
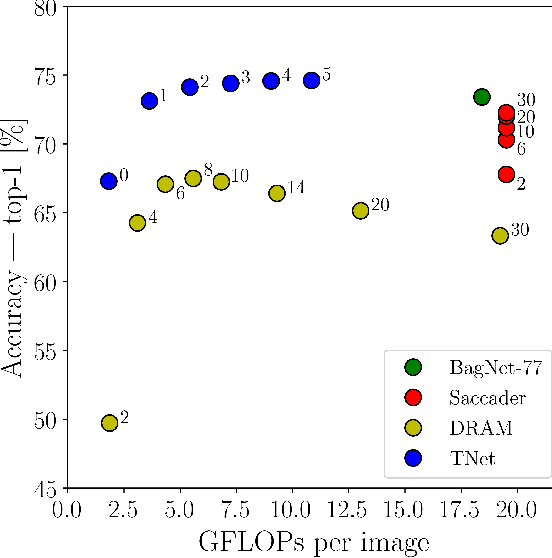
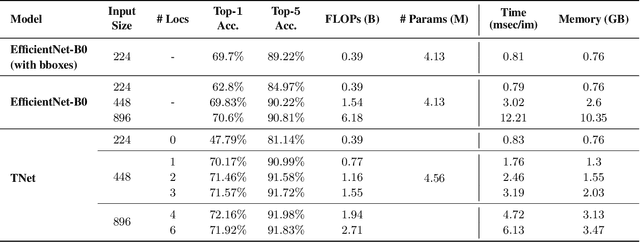
Deep neural networks (DNNs) are typically optimized for a specific input resolution (e.g. $224 \times 224$ px) and their adoption to inputs of higher resolution (e.g., satellite or medical images) remains challenging, as it leads to excessive computation and memory overhead, and may require substantial engineering effort (e.g., streaming). We show that multi-scale hard-attention can be an effective solution to this problem. We propose a novel architecture, TNet, which traverses an image pyramid in a top-down fashion, visiting only the most informative regions along the way. We compare our model against strong hard-attention baselines, achieving a better trade-off between resources and accuracy on ImageNet. We further verify the efficacy of our model on satellite images (fMoW dataset) of size up to $896 \times 896$ px. In addition, our hard-attention mechanism guarantees predictions with a degree of interpretability, without extra cost beyond inference. We also show that we can reduce data acquisition and annotation cost, since our model attends only to a fraction of the highest resolution content, while using only image-level labels without bounding boxes.