 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAWKS: Evolving Challenging Benchmark Sets for Cluster Analysis
Paper and Code

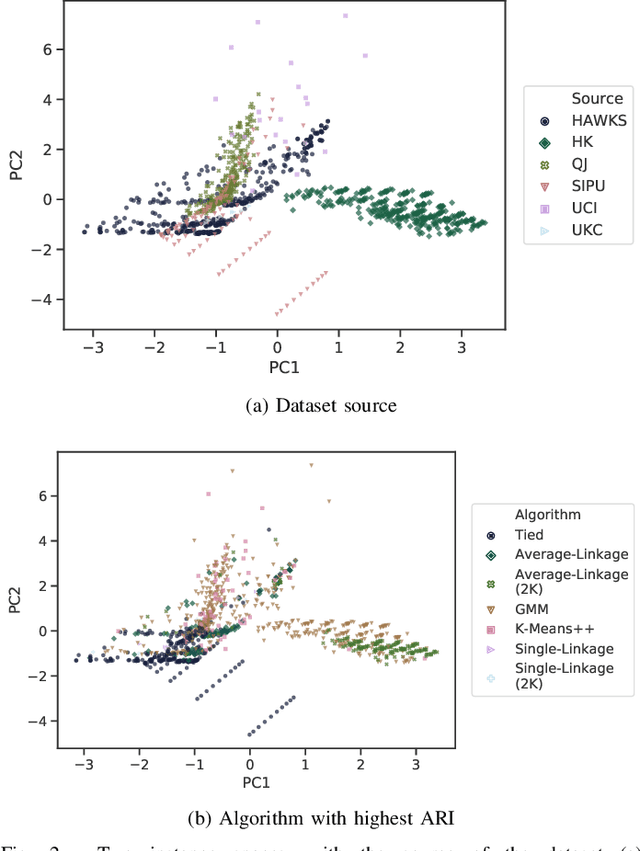
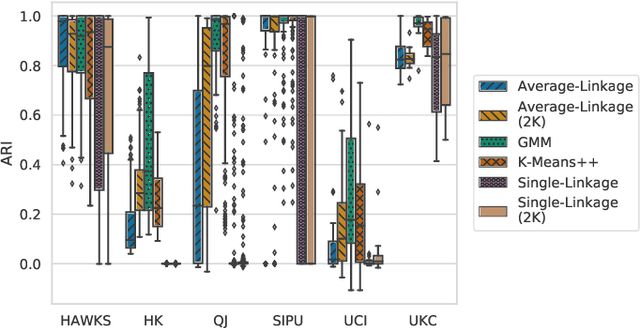
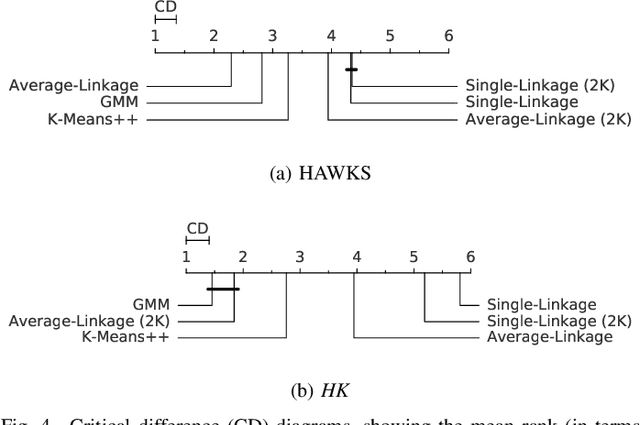
Comprehensive benchmarking of clustering algorithms is rendered difficult by two key factors: (i)~the elusiveness of a unique mathematical definition of this unsupervised learning approach and (ii)~dependencies between the generating models or clustering criteria adopted by some clustering algorithms and indices for internal cluster validation. Consequently, there is no consensus regarding the best practice for rigorous benchmarking, and whether this is possible at all outside the context of a given application. Here, we argue that synthetic datasets must continue to play an important role in the evaluation of clustering algorithms, but that this necessitates constructing benchmarks that appropriately cover the diverse set of properties that impact clustering algorithm performance. Through our framework, HAWKS, we demonstrate the important role evolutionary algorithms play to support flexible generation of such benchmarks, allowing simple modification and extension. We illustrate two possible uses of our framework: (i)~the evolution of benchmark data consistent with a set of hand-derived properties and (ii)~the generation of datasets that tease out performance differences between a given pair of algorithms. Our work has implications for the design of clustering benchmarks that sufficiently challenge a broad range of algorithms, and for furthering insight into the strengths and weaknesses of specific approaches.