 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Value Weighted Regression: Reinforcement Learning with Limited Data
Paper and Code
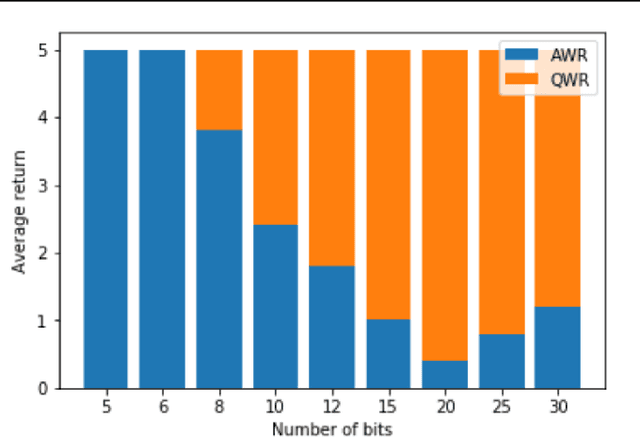
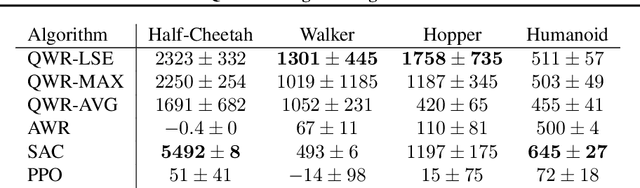
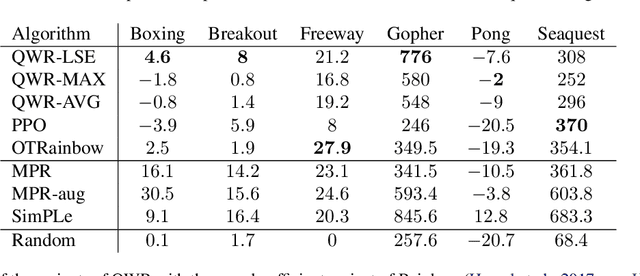
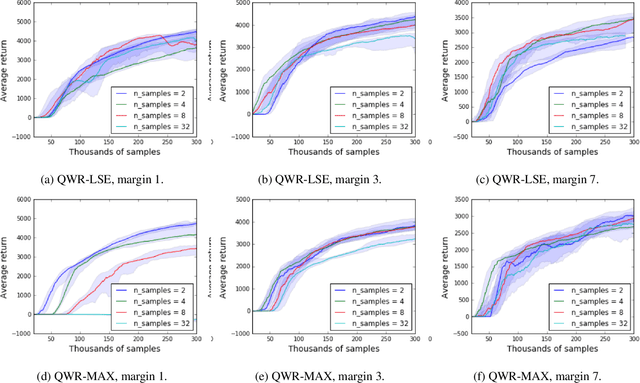
Sample efficiency and performance in the offline setting have emerged as significant challenges of deep reinforcement learning. We introduce Q-Value Weighted Regression (QWR), a simple RL algorithm that excels in these aspects. QWR is an extension of Advantage Weighted Regression (AWR), an off-policy actor-critic algorithm that performs very well on continuous control tasks, also in the offline setting, but has low sample efficiency and struggles with high-dimensional observation spaces. We perform an analysis of AWR that explains its shortcomings and use these insights to motivate QWR. We show experimentally that QWR matches the state-of-the-art algorithms both on tasks with continuous and discrete actions. In particular, QWR yields results on par with SAC on the MuJoCo suite and - with the same set of hyperparameters - yields results on par with a highly tuned Rainbow implementation on a set of Atari games. We also verify that QWR performs well in the offline RL setting.