 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-View Approach To Audio-Visual Speaker Verification
Paper and Code
Feb 11, 2021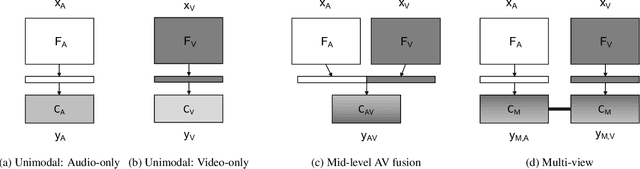
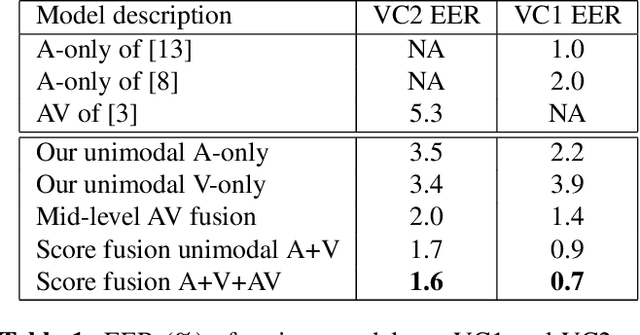

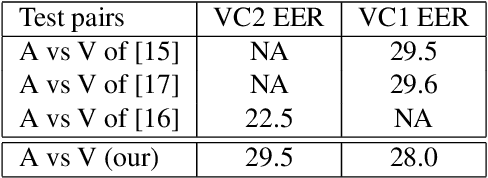
Although speaker verification has conventionally been an audio-only task, some practical applications provide both audio and visual streams of input. In these cases, the visual stream provides complementary information and can often be leveraged in conjunction with the acoustics of speech to improve verification performance. In this study, we explore audio-visual approaches to speaker verification, starting with standard fusion techniques to learn joint audio-visual (AV) embeddings, and then propose a novel approach to handle cross-modal verification at test time. Specifically, we investigate unimodal and concatenation based AV fusion and report the lowest AV equal error rate (EER) of 0.7% on the VoxCeleb1 dataset using our best system. As these methods lack the ability to do cross-modal verification, we introduce a multi-view model which uses a shared classifier to map audio and video into the same space. This new approach achieves 28% EER on VoxCeleb1 in the challenging testing condition of cross-modal verification.