 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization Is Deceiving Us, and How to Stop It
Paper and Code
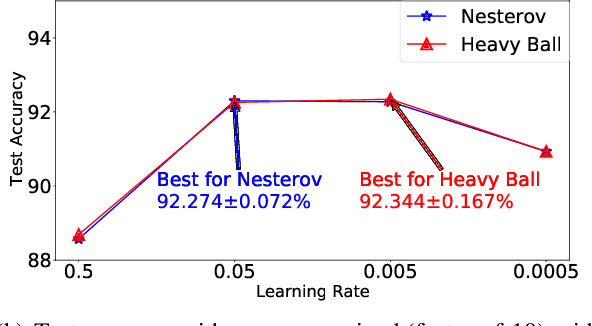
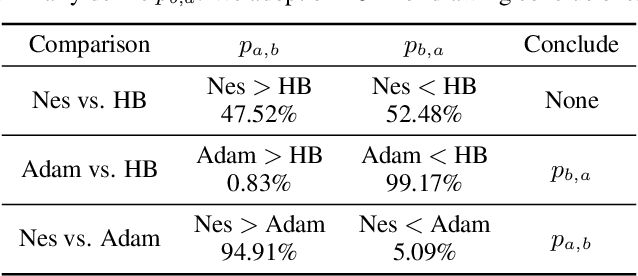
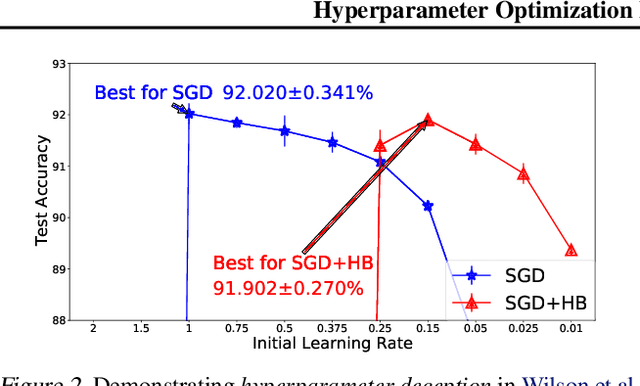
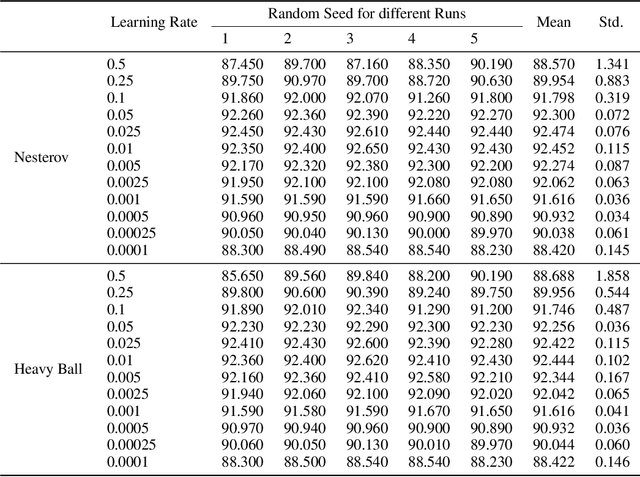
While hyperparameter optimization (HPO) is known to greatly impact learning algorithm performance, it is often treated as an empirical afterthought. Recent empirical works have highlighted the risk of this second-rate treatment of HPO. They show that inconsistent performance results, based on choice of hyperparameter subspace to search, are a widespread problem in ML research. When comparing two algorithms, J and K searching one subspace can yield the conclusion that J outperforms K, whereas searching another can entail the opposite result. In short, your choice of hyperparameters can deceive you. We provide a theoretical complement to this prior work: We analytically characterize this problem, which we term hyperparameter deception, and show that grid search is inherently deceptive. We prove a defense with guarantees against deception, and demonstrate a defense in practice.