 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Quantized Neural Networks on FPGAs with FINN
Paper and Code
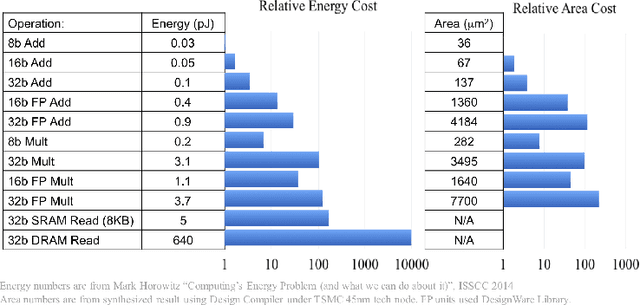

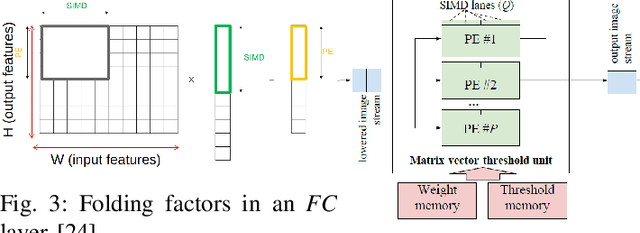
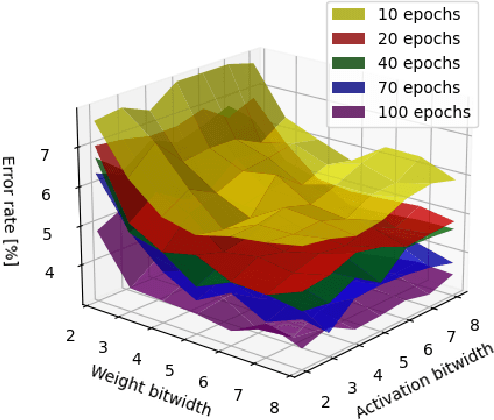
The ever-growing cost of both training and inference for state-of-the-art neural networks has brought literature to look upon ways to cut off resources used with a minimal impact on accuracy. Using lower precision comes at the cost of negligible loss in accuracy. While training neural networks may require a powerful setup, deploying a network must be possible on low-power and low-resource hardware architectures. Reconfigurable architectures have proven to be more powerful and flexible than GPUs when looking at a specific application. This article aims to assess the impact of mixed-precision when applied to neural networks deployed on FPGAs. While several frameworks exist that create tools to deploy neural networks using reduced-precision, few of them assess the importance of quantization and the framework quality. FINN and Brevitas, two frameworks from Xilinx labs, are used to assess the impact of quantization on neural networks using 2 to 8 bit precisions and weights with several parallelization configurations. Equivalent accuracy can be obtained using lower-precision representation and enough training. However, the compressed network can be better parallelized allowing the deployed network throughput to be 62 times faster. The benchmark set up in this work is available in a public repository (https://github.com/QDucasse/nn benchmark).