 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedH2L: Federated Learning with Model and Statistical Heterogeneity
Paper and Code
Jan 27, 2021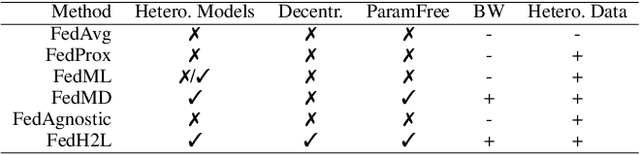
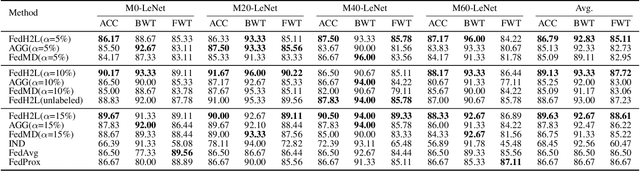
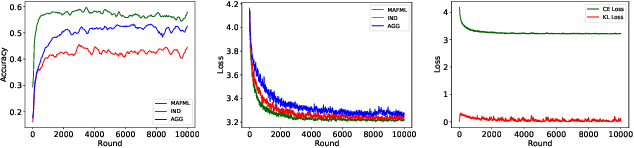
Federated learning (FL) enables distributed participants to collectively learn a strong global model without sacrificing their individual data privacy. Mainstream FL approaches require each participant to share a common network architecture and further assume that data are are sampled IID across participants. However, in real-world deployments participants may require heterogeneous network architectures; and the data distribution is almost certainly non-uniform across participants. To address these issues we introduce FedH2L, which is agnostic to both the model architecture and robust to different data distributions across participants. In contrast to approaches sharing parameters or gradients, FedH2L relies on mutual distillation, exchanging only posteriors on a shared seed set between participants in a decentralized manner. This makes it extremely bandwidth efficient, model agnostic, and crucially produces models capable of performing well on the whole data distribution when learning from heterogeneous silos.