 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Paths Perspective for Pruning at Initialization
Paper and Code
Jan 26, 2021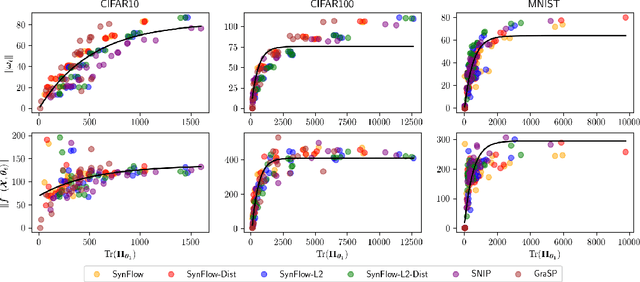
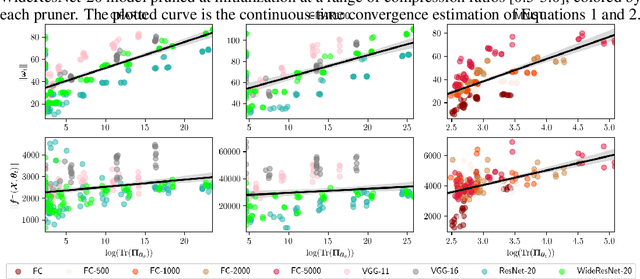
A number of recent approaches have been proposed for pruning neural network parameters at initialization with the goal of reducing the size and computational burden of models while minimally affecting their training dynamics and generalization performance. While each of these approaches have some amount of well-founded motivation, a rigorous analysis of the effect of these pruning methods on network training dynamics and their formal relationship to each other has thus far received little attention. Leveraging recent theoretical approximations provided by the Neural Tangent Kernel, we unify a number of popular approaches for pruning at initialization under a single path-centric framework. We introduce the Path Kernel as the data-independent factor in a decomposition of the Neural Tangent Kernel and show the global structure of the Path Kernel can be computed efficiently. This Path Kernel decomposition separates the architectural effects from the data-dependent effects within the Neural Tangent Kernel, providing a means to predict the convergence dynamics of a network from its architecture alone. We analyze the use of this structure in approximating training and generalization performance of networks in the absence of data across a number of initialization pruning approaches. Observing the relationship between input data and paths and the relationship between the Path Kernel and its natural norm, we additionally propose two augmentations of the SynFlow algorithm for pruning at initialization.