 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Domain Generalization Baselines
Paper and Code
Jan 27, 2021
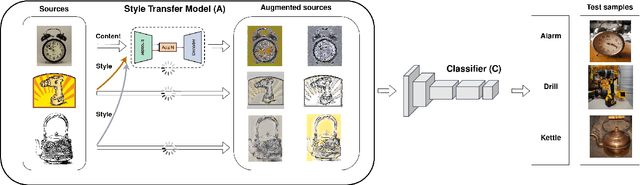
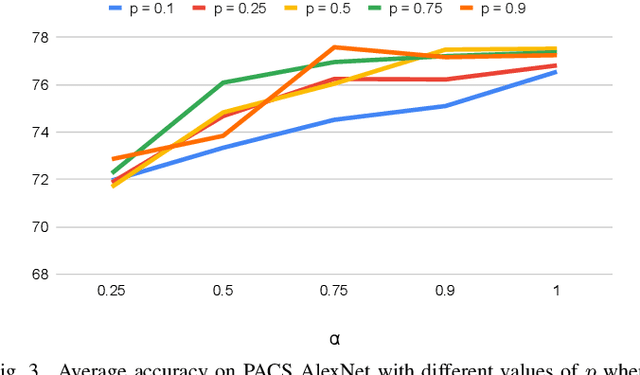
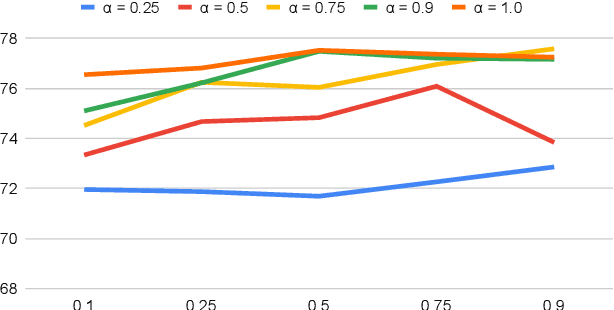
Despite being very powerful in standard learning settings, deep learning models can be extremely brittle when deployed in scenarios different from those on which they were trained. Domain generalization methods investigate this problem and data augmentation strategies have shown to be helpful tools to increase data variability, supporting model robustness across domains. In our work we focus on style transfer data augmentation and we present how it can be implemented with a simple and inexpensive strategy to improve generalization. Moreover, we analyze the behavior of current state of the art domain generalization methods when integrated with this augmentation solution: our thorough experimental evaluation shows that their original effect almost always disappears with respect to the augmented baseline. This issue open new scenarios for domain generalization research, highlighting the need of novel methods properly able to take advantage of the introduced data variability.