 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Clustering of Short Text Streams Using Efficient Cluster Indexing and Dynamic Similarity Thresholds
Paper and Code
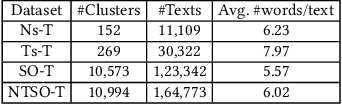

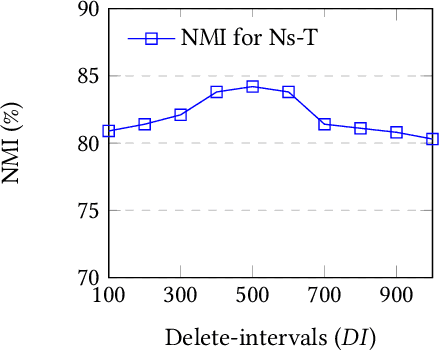
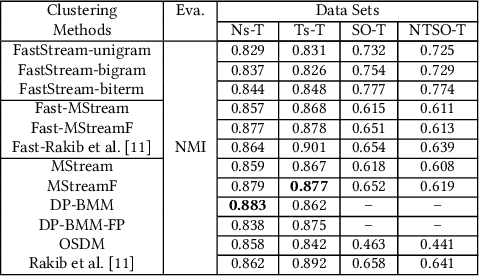
Short text stream clustering is an important but challenging task since massive amount of text is generated from different sources such as micro-blogging, question-answering, and social news aggregation websites. One of the major challenges of clustering such massive amount of text is to cluster them within a reasonable amount of time. The existing state-of-the-art short text stream clustering methods can not cluster such massive amount of text within a reasonable amount of time as they compute similarities between a text and all the existing clusters to assign that text to a cluster. To overcome this challenge, we propose a fast short text stream clustering method (called FastStream) that efficiently index the clusters using inverted index and compute similarity between a text and a selected number of clusters while assigning a text to a cluster. In this way, we not only reduce the running time of our proposed method but also reduce the running time of several state-of-the-art short text stream clustering methods. FastStream assigns a text to a cluster (new or existing) using the dynamically computed similarity thresholds based on statistical measure. Thus our method efficiently deals with the concept drift problem. Experimental results demonstrate that FastStream outperforms the state-of-the-art short text stream clustering methods by a significant margin on several short text datasets. In addition, the running time of FastStream is several orders of magnitude faster than that of the state-of-the-art methods.