 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Transducer: A Highly-efficient Speech Recognition Model on Edge Devices
Paper and Code
Feb 07, 2021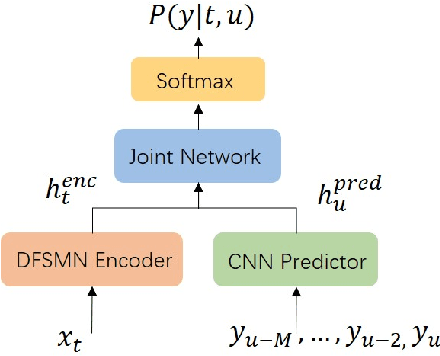

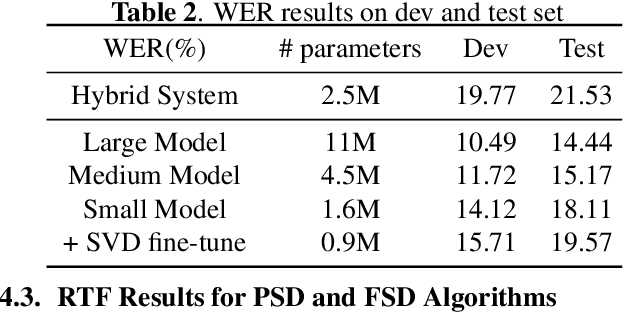
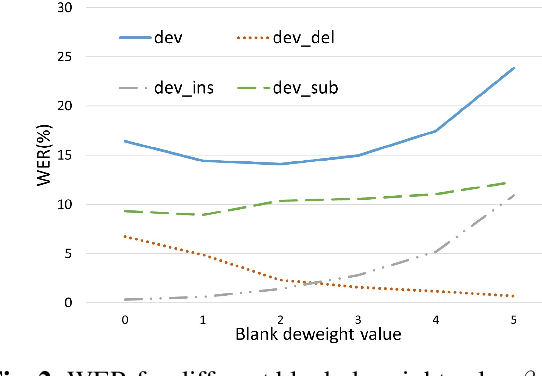
This paper proposes an extremely lightweight phone-based transducer model with a tiny decoding graph on edge devices. First, a phone synchronous decoding (PSD) algorithm based on blank label skipping is first used to speed up the transducer decoding process. Then, to decrease the deletion errors introduced by the high blank score, a blank label deweighting approach is proposed. To reduce parameters and computation, deep feedforward sequential memory network (DFSMN) layers are used in the transducer encoder, and a CNN-based stateless predictor is adopted. SVD technology compresses the model further. WFST-based decoding graph takes the context-independent (CI) phone posteriors as input and allows us to flexibly bias user-specific information. Finally, with only 0.9M parameters after SVD, our system could give a relative 9.1% - 20.5% improvement compared with a bigger conventional hybrid system on edge devices.