 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Navigation and Docking of an Autonomous Robot Mower using Reinforcement Learning and Computer Vision
Paper and Code
Jan 15, 2021
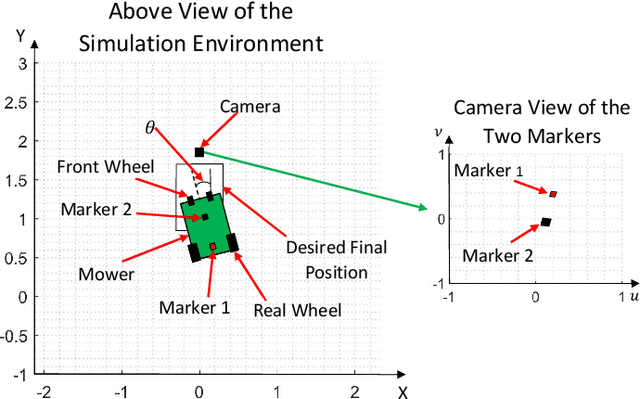
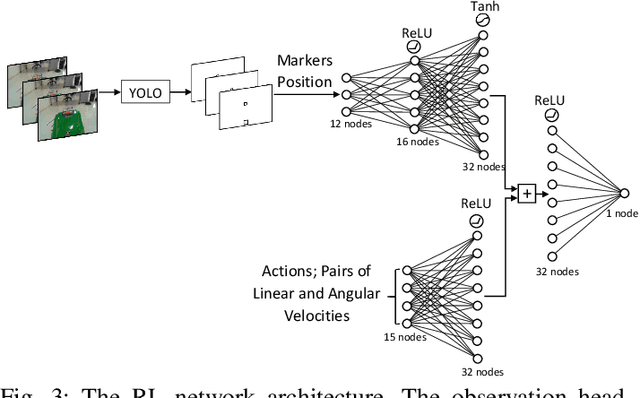
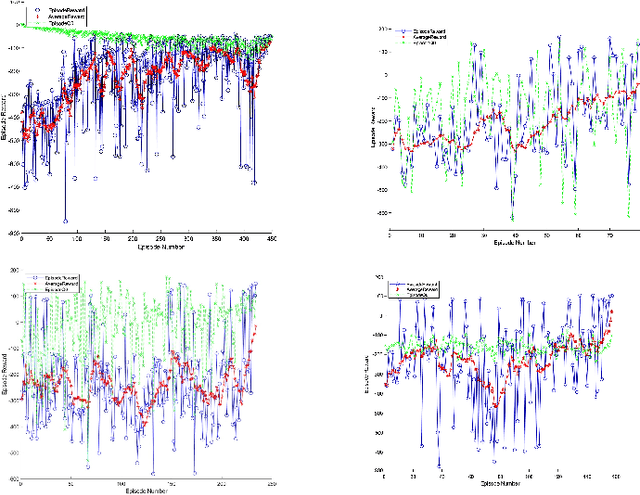
We demonstrate a successful navigation and docking control system for the John Deere Tango autonomous mower, using only a single camera as the input. This vision-only system is of interest because it is inexpensive, simple for production, and requires no external sensing. This is in contrast to existing systems that rely on integrated position sensors and global positioning system (GPS) technologies. To produce our system we combined a state-of-the-art object detection architecture, YOLO, with a reinforcement learning (RL) architecture, Double Deep QNetworks (Double DQN). The object detection network identifies features on the mower and passes its output to the RL network, providing it with a low-dimensional representation that enables rapid and robust training. Finally, the RL network learns how to navigate the machine to the desired spot in a custom simulation environment. When tested on mower hardware the system is able to dock with centimeter-level accuracy from arbitrary initial locations and orientations.