 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
Paper and Code
Jan 14, 2021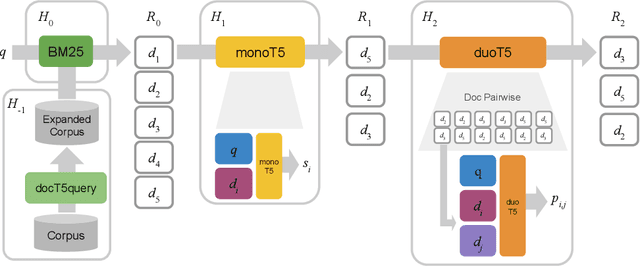
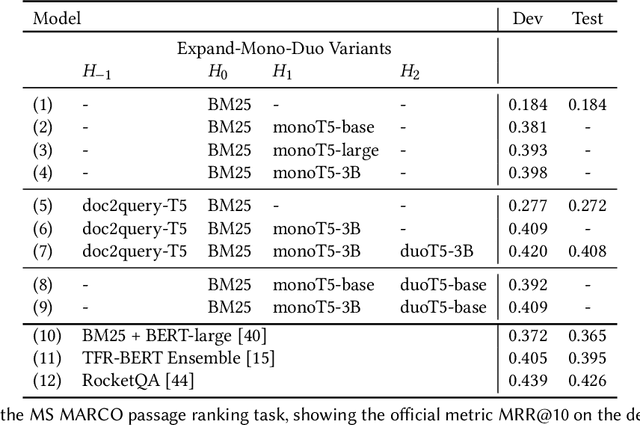
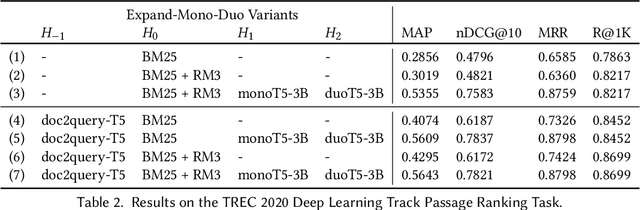
We propose a design pattern for tackling text ranking problems, dubbed "Expando-Mono-Duo", that has been empirically validated for a number of ad hoc retrieval tasks in different domains. At the core, our design relies on pretrained sequence-to-sequence models within a standard multi-stage ranking architecture. "Expando" refers to the use of document expansion techniques to enrich keyword representations of texts prior to inverted indexing. "Mono" and "Duo" refer to components in a reranking pipeline based on a pointwise model and a pairwise model that rerank initial candidates retrieved using keyword search. We present experimental results from the MS MARCO passage and document ranking tasks, the TREC 2020 Deep Learning Track, and the TREC-COVID challenge that validate our design. In all these tasks, we achieve effectiveness that is at or near the state of the art, in some cases using a zero-shot approach that does not exploit any training data from the target task. To support replicability, implementations of our design pattern are open-sourced in the Pyserini IR toolkit and PyGaggle neural reranking library.