 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Together -- An Ensemble Learner for Combining the Results of Ready-made Entity Linking Systems
Paper and Code
Jan 14, 2021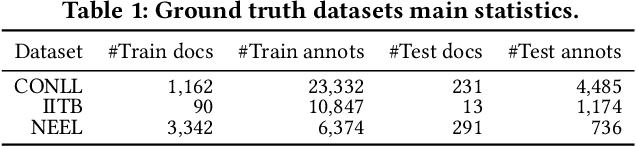
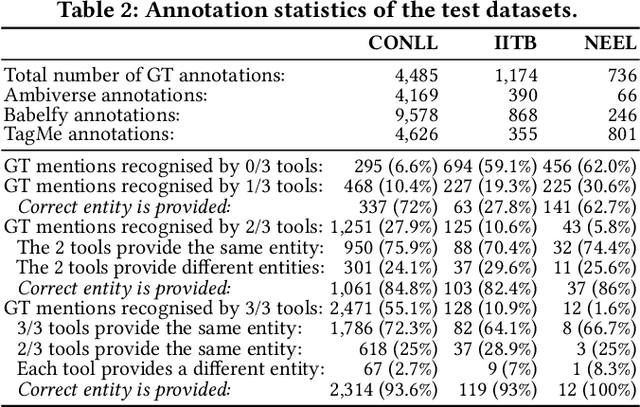
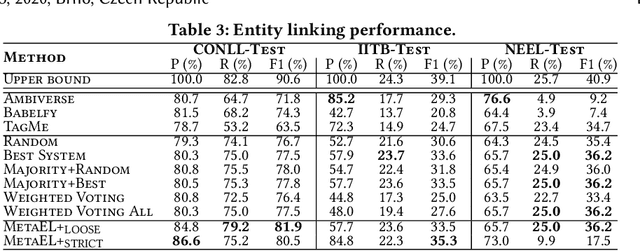
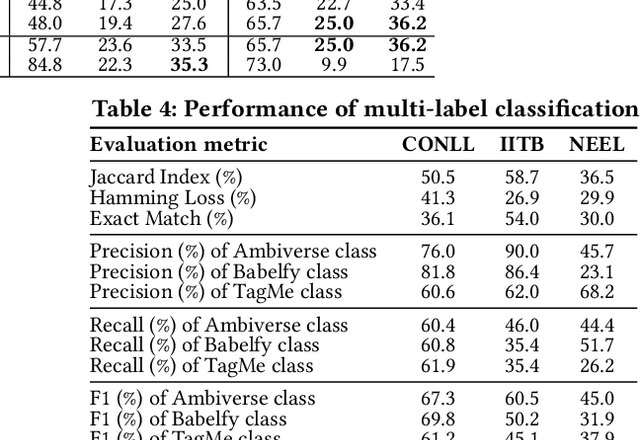
Entity linking (EL) is the task of automatically identifying entity mentions in text and resolving them to a corresponding entity in a reference knowledge base like Wikipedia. Throughout the past decade, a plethora of EL systems and pipelines have become available, where performance of individual systems varies heavily across corpora, languages or domains. Linking performance varies even between different mentions in the same text corpus, where, for instance, some EL approaches are better able to deal with short surface forms while others may perform better when more context information is available. To this end, we argue that performance may be optimised by exploiting results from distinct EL systems on the same corpus, thereby leveraging their individual strengths on a per-mention basis. In this paper, we introduce a supervised approach which exploits the output of multiple ready-made EL systems by predicting the correct link on a per-mention basis. Experimental results obtained on existing ground truth datasets and exploiting three state-of-the-art EL systems show the effectiveness of our approach and its capacity to significantly outperform the individual EL systems as well as a set of baseline methods.