 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopula Flows for Synthetic Data Generation
Paper and Code
Jan 03, 2021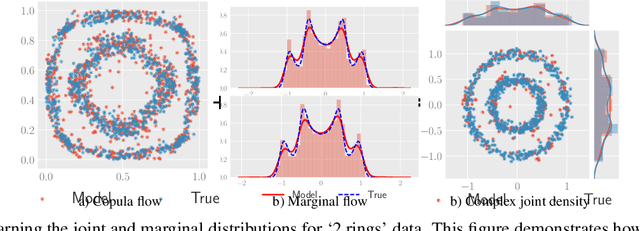
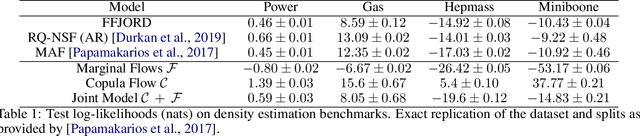
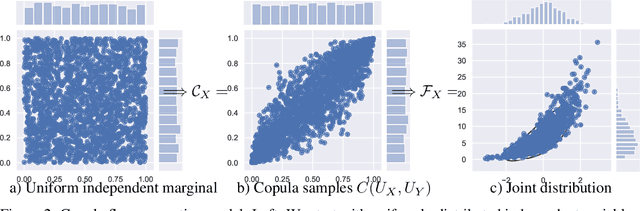
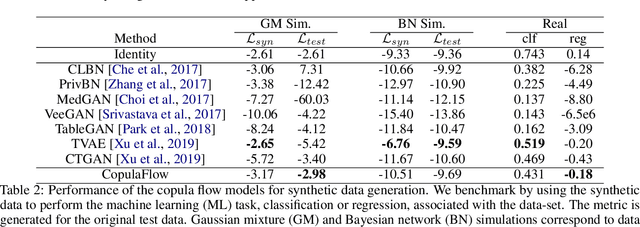
The ability to generate high-fidelity synthetic data is crucial when available (real) data is limited or where privacy and data protection standards allow only for limited use of the given data, e.g., in medical and financial data-sets. Current state-of-the-art methods for synthetic data generation are based on generative models, such as Generative Adversarial Networks (GANs). Even though GANs have achieved remarkable results in synthetic data generation, they are often challenging to interpret.Furthermore, GAN-based methods can suffer when used with mixed real and categorical variables.Moreover, loss function (discriminator loss) design itself is problem specific, i.e., the generative model may not be useful for tasks it was not explicitly trained for. In this paper, we propose to use a probabilistic model as a synthetic data generator. Learning the probabilistic model for the data is equivalent to estimating the density of the data. Based on the copula theory, we divide the density estimation task into two parts, i.e., estimating univariate marginals and estimating the multivariate copula density over the univariate marginals. We use normalising flows to learn both the copula density and univariate marginals. We benchmark our method on both simulated and real data-sets in terms of density estimation as well as the ability to generate high-fidelity synthetic data