 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAraELECTRA: Pre-Training Text Discriminators for Arabic Language Understanding
Paper and Code
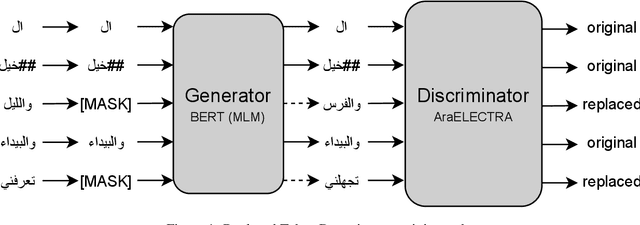
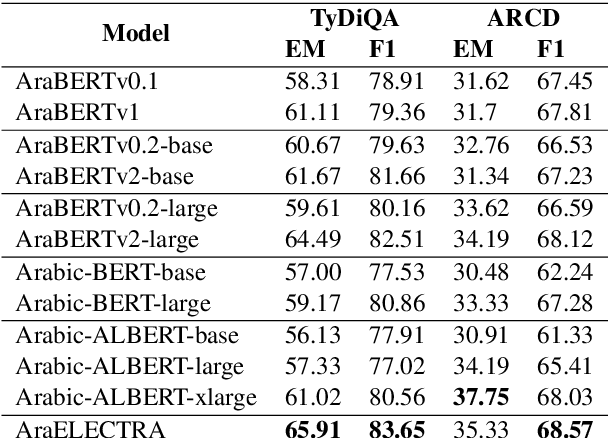
Advances in English language representation enabled a more sample-efficient pre-training task by Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA). Which, instead of training a model to recover masked tokens, it trains a discriminator model to distinguish true input tokens from corrupted tokens that were replaced by a generator network. On the other hand, current Arabic language representation approaches rely only on pretraining via masked language modeling. In this paper, we develop an Arabic language representation model, which we name AraELECTRA. Our model is pretrained using the replaced token detection objective on large Arabic text corpora. We evaluate our model on two Arabic reading comprehension tasks, and we show that AraELECTRA outperforms current state-of-the-art Arabic language representation models given the same pretraining data and with even a smaller model size.