 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Run with Potential-Based Reward Shaping and Demonstrations from Video Data
Paper and Code
Dec 16, 2020
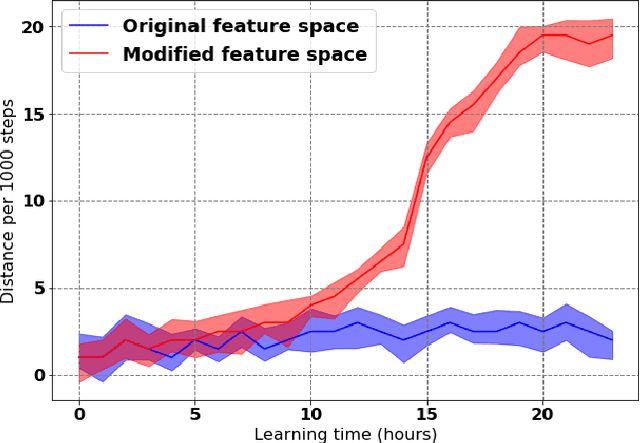
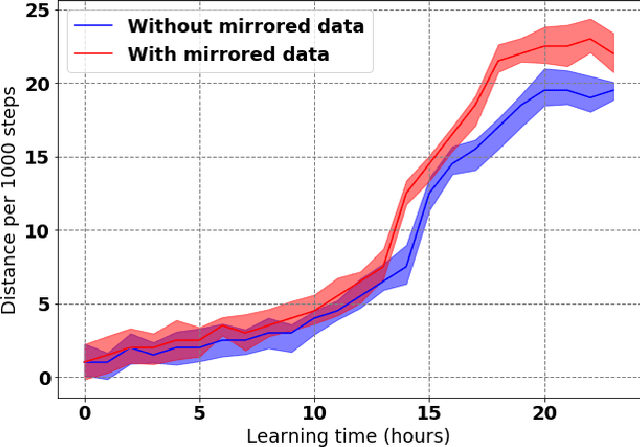
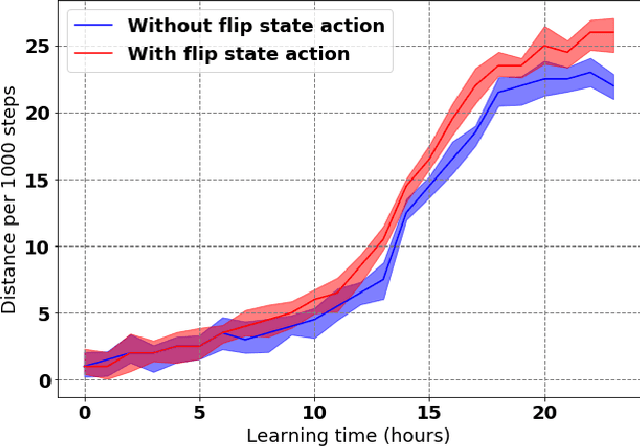
Learning to produce efficient movement behaviour for humanoid robots from scratch is a hard problem, as has been illustrated by the "Learning to run" competition at NIPS 2017. The goal of this competition was to train a two-legged model of a humanoid body to run in a simulated race course with maximum speed. All submissions took a tabula rasa approach to reinforcement learning (RL) and were able to produce relatively fast, but not optimal running behaviour. In this paper, we demonstrate how data from videos of human running (e.g. taken from YouTube) can be used to shape the reward of the humanoid learning agent to speed up the learning and produce a better result. Specifically, we are using the positions of key body parts at regular time intervals to define a potential function for potential-based reward shaping (PBRS). Since PBRS does not change the optimal policy, this approach allows the RL agent to overcome sub-optimalities in the human movements that are shown in the videos. We present experiments in which we combine selected techniques from the top ten approaches from the NIPS competition with further optimizations to create an high-performing agent as a baseline. We then demonstrate how video-based reward shaping improves the performance further, resulting in an RL agent that runs twice as fast as the baseline in 12 hours of training. We furthermore show that our approach can overcome sub-optimal running behaviour in videos, with the learned policy significantly outperforming that of the running agent from the video.