 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Distributed Online Meta-Learning via Multi-Agent Collaboration under Limited Communication
Paper and Code
Dec 19, 2020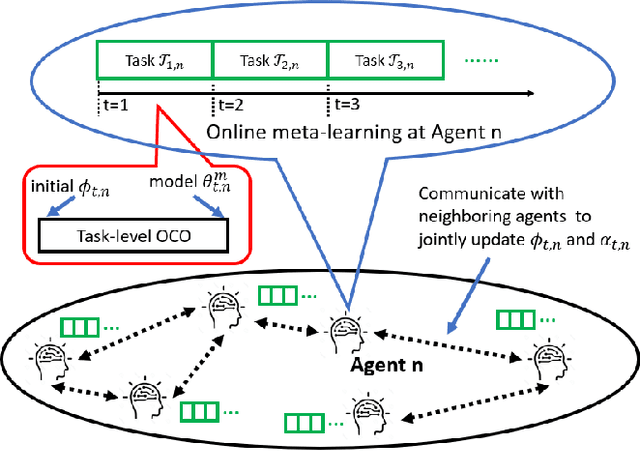
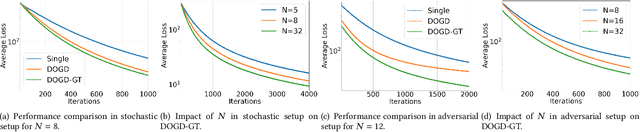
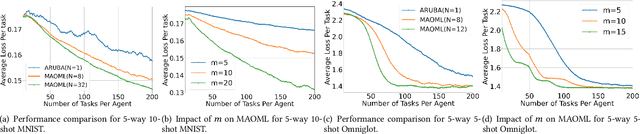
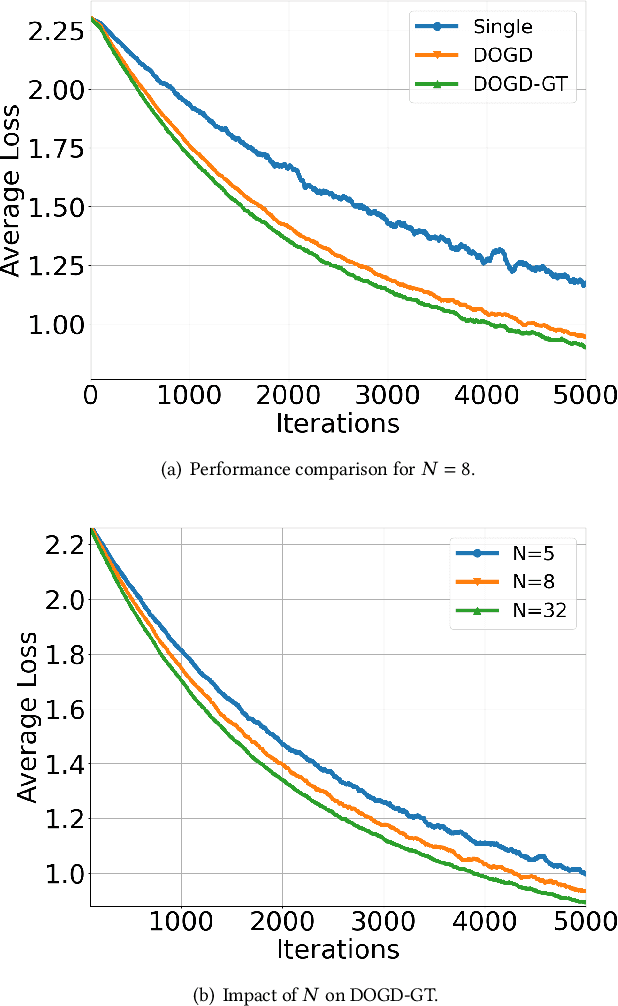
Online meta-learning is emerging as an enabling technique for achieving edge intelligence in the IoT ecosystem. Nevertheless, to learn a good meta-model for within-task fast adaptation, a single agent alone has to learn over many tasks, and this is the so-called 'cold-start' problem. Observing that in a multi-agent network the learning tasks across different agents often share some model similarity, we ask the following fundamental question: "Is it possible to accelerate the online meta-learning across agents via limited communication and if yes how much benefit can be achieved? " To answer this question, we propose a multi-agent online meta-learning framework and cast it as an equivalent two-level nested online convex optimization (OCO) problem. By characterizing the upper bound of the agent-task-averaged regret, we show that the performance of multi-agent online meta-learning depends heavily on how much an agent can benefit from the distributed network-level OCO for meta-model updates via limited communication, which however is not well understood. To tackle this challenge, we devise a distributed online gradient descent algorithm with gradient tracking where each agent tracks the global gradient using only one communication step with its neighbors per iteration, and it results in an average regret $O(\sqrt{T/N})$ per agent, indicating that a factor of $\sqrt{1/N}$ speedup over the optimal single-agent regret $O(\sqrt{T})$ after $T$ iterations, where $N$ is the number of agents. Building on this sharp performance speedup, we next develop a multi-agent online meta-learning algorithm and show that it can achieve the optimal task-average regret at a faster rate of $O(1/\sqrt{NT})$ via limited communication, compared to single-agent online meta-learning. Extensive experiments corroborate the theoretic results.