 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple or Complex? Learning to Predict Readability of Bengali Texts
Paper and Code
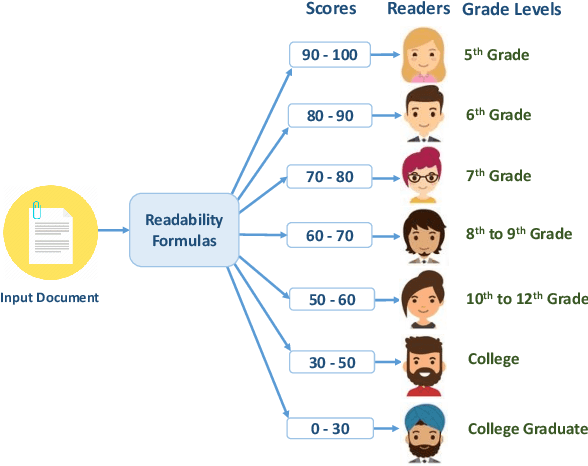
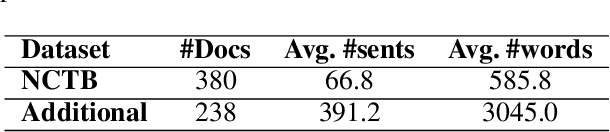
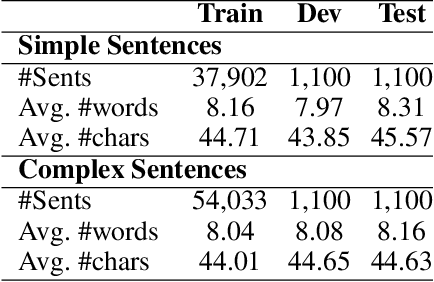

Determining the readability of a text is the first step to its simplification. In this paper, we present a readability analysis tool capable of analyzing text written in the Bengali language to provide in-depth information on its readability and complexity. Despite being the 7th most spoken language in the world with 230 million native speakers, Bengali suffers from a lack of fundamental resources for natural language processing. Readability related research of the Bengali language so far can be considered to be narrow and sometimes faulty due to the lack of resources. Therefore, we correctly adopt document-level readability formulas traditionally used for U.S. based education system to the Bengali language with a proper age-to-age comparison. Due to the unavailability of large-scale human-annotated corpora, we further divide the document-level task into sentence-level and experiment with neural architectures, which will serve as a baseline for the future works of Bengali readability prediction. During the process, we present several human-annotated corpora and dictionaries such as a document-level dataset comprising 618 documents with 12 different grade levels, a large-scale sentence-level dataset comprising more than 96K sentences with simple and complex labels, a consonant conjunct count algorithm and a corpus of 341 words to validate the effectiveness of the algorithm, a list of 3,396 easy words, and an updated pronunciation dictionary with more than 67K words. These resources can be useful for several other tasks of this low-resource language. We make our Code & Dataset publicly available at https://github.com/tafseer-nayeem/BengaliReadability} for reproduciblity.