 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Confusion Learning to Enhance Text Classification Models
Paper and Code
Dec 09, 2020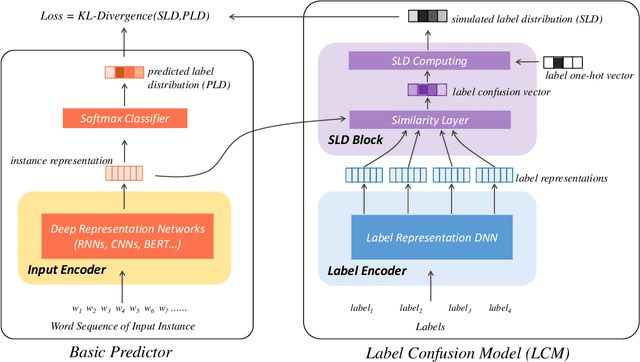
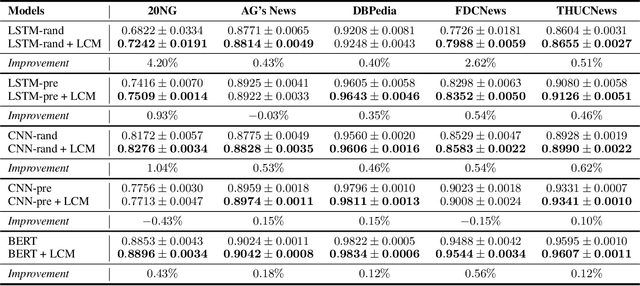
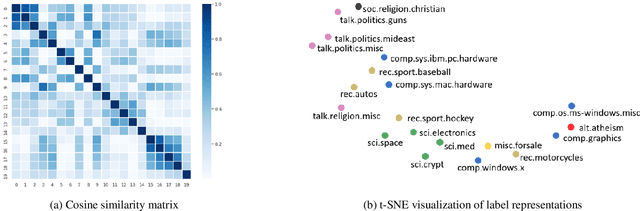

Representing a true label as a one-hot vector is a common practice in training text classification models. However, the one-hot representation may not adequately reflect the relation between the instances and labels, as labels are often not completely independent and instances may relate to multiple labels in practice. The inadequate one-hot representations tend to train the model to be over-confident, which may result in arbitrary prediction and model overfitting, especially for confused datasets (datasets with very similar labels) or noisy datasets (datasets with labeling errors). While training models with label smoothing (LS) can ease this problem in some degree, it still fails to capture the realistic relation among labels. In this paper, we propose a novel Label Confusion Model (LCM) as an enhancement component to current popular text classification models. LCM can learn label confusion to capture semantic overlap among labels by calculating the similarity between instances and labels during training and generate a better label distribution to replace the original one-hot label vector, thus improving the final classification performance. Extensive experiments on five text classification benchmark datasets reveal the effectiveness of LCM for several widely used deep learning classification models. Further experiments also verify that LCM is especially helpful for confused or noisy datasets and superior to the label smoothing method.