 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Training of Graph Convolutional Networks using Subgraph Approximation
Paper and Code
Dec 09, 2020
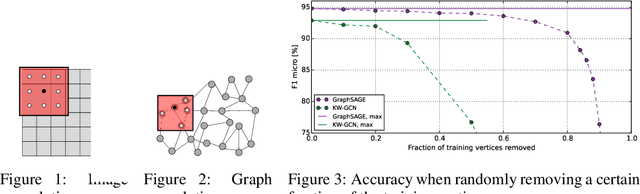

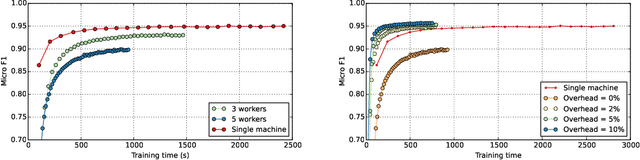
Modern machine learning techniques are successfully being adapted to data modeled as graphs. However, many real-world graphs are typically very large and do not fit in memory, often making the problem of training machine learning models on them intractable. Distributed training has been successfully employed to alleviate memory problems and speed up training in machine learning domains in which the input data is assumed to be independently identical distributed (i.i.d). However, distributing the training of non i.i.d data such as graphs that are used as training inputs in Graph Convolutional Networks (GCNs) causes accuracy problems since information is lost at the graph partitioning boundaries. In this paper, we propose a training strategy that mitigates the lost information across multiple partitions of a graph through a subgraph approximation scheme. Our proposed approach augments each sub-graph with a small amount of edge and vertex information that is approximated from all other sub-graphs. The subgraph approximation approach helps the distributed training system converge at single-machine accuracy, while keeping the memory footprint low and minimizing synchronization overhead between the machines.