 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impossibility of Convergence of Mixed Strategies with No Regret Learning
Paper and Code
Dec 03, 2020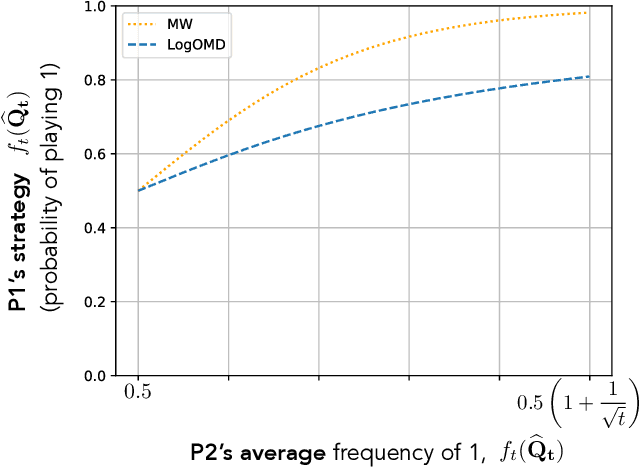
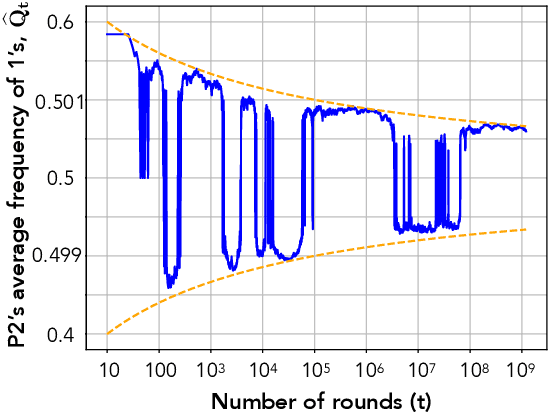
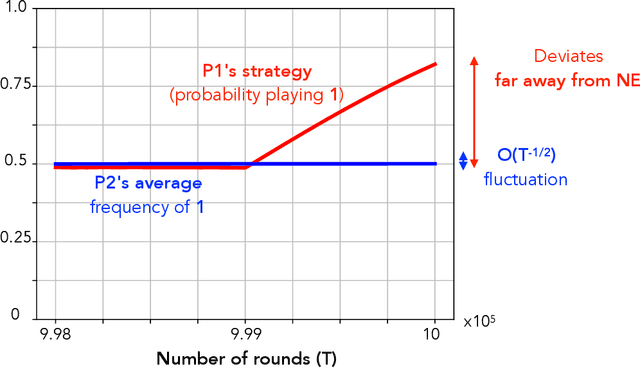
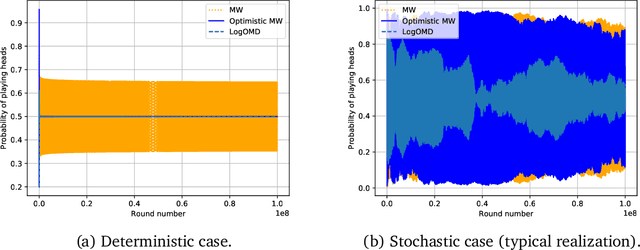
We study convergence properties of the mixed strategies that result from a general class of optimal no regret learning strategies in a repeated game setting where the stage game is any 2 by 2 competitive game (i.e. game for which all the Nash equilibria (NE) of the game are completely mixed). We consider the class of strategies whose information set at each step is the empirical average of the opponent's realized play (and the step number), that we call mean based strategies. We first show that there does not exist any optimal no regret, mean based strategy for player 1 that would result in the convergence of her mixed strategies (in probability) against an opponent that plays his Nash equilibrium mixed strategy at each step. Next, we show that this last iterate divergence necessarily occurs if player 2 uses any adaptive strategy with a minimal randomness property. This property is satisfied, for example, by any fixed sequence of mixed strategies for player 2 that converges to NE. We conjecture that this property holds when both players use optimal no regret learning strategies against each other, leading to the divergence of the mixed strategies with a positive probability. Finally, we show that variants of mean based strategies using recency bias, which have yielded last iterate convergence in deterministic min max optimization, continue to lead to this last iterate divergence. This demonstrates a crucial difference in outcomes between using the opponent's mixtures and realizations to make strategy updates.