 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Few-Shot Audio Classification
Paper and Code
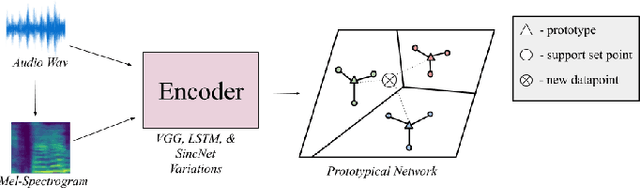
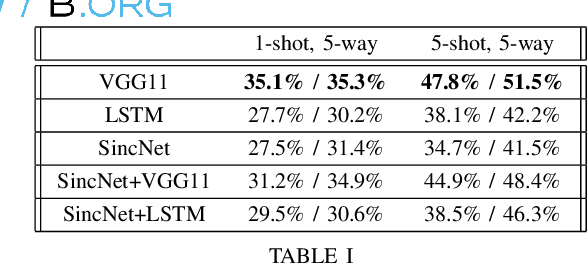
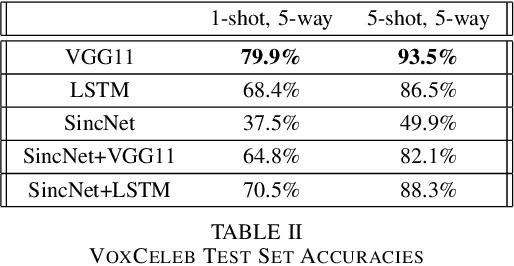

Advances in deep learning have resulted in state-of-the-art performance for many audio classification tasks but, unlike humans, these systems traditionally require large amounts of data to make accurate predictions. Not every person or organization has access to those resources, and the organizations that do, like our field at large, do not reflect the demographics of our country. Enabling people to use machine learning without significant resource hurdles is important, because machine learning is an increasingly useful tool for solving problems, and can solve a broader set of problems when put in the hands of a broader set of people. Few-shot learning is a type of machine learning designed to enable the model to generalize to new classes with very few examples. In this research, we address two audio classification tasks (speaker identification and activity classification) with the Prototypical Network few-shot learning algorithm, and assess performance of various encoder architectures. Our encoders include recurrent neural networks, as well as one- and two-dimensional convolutional neural networks. We evaluate our model for speaker identification on the VoxCeleb dataset and ICSI Meeting Corpus, obtaining 5-shot 5-way accuracies of 93.5% and 54.0%, respectively. We also evaluate for activity classification from audio using few-shot subsets of the Kinetics~600 dataset and AudioSet, both drawn from Youtube videos, obtaining 51.5% and 35.2% accuracy, respectively.