 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Retrieval and Synthesis (X-MRS): Closing the modality gap in shared subspace
Paper and Code
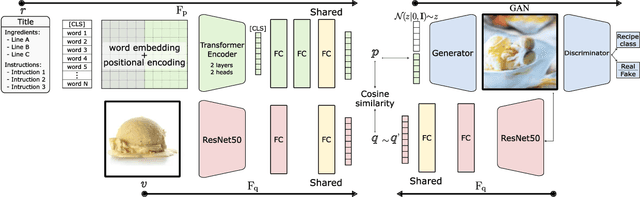
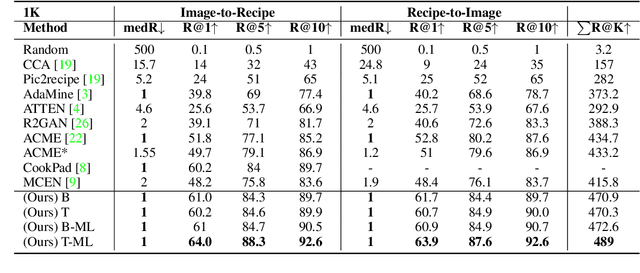
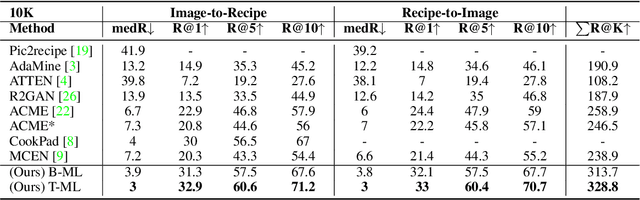

Computational food analysis (CFA), a broad set of methods that attempt to automate food understanding, naturally requires analysis of multi-modal evidence of a particular food or dish, e.g. images, recipe text, preparation video, nutrition labels, etc. A key to making CFA possible is multi-modal shared subspace learning, which in turn can be used for cross-modal retrieval and/or synthesis, particularly, between food images and their corresponding textual recipes. In this work we propose a simple yet novel architecture for shared subspace learning, which is used to tackle the food image-to-recipe retrieval problem. Our proposed method employs an effective transformer based multilingual recipe encoder coupled with a traditional image embedding architecture. Experimental analysis on the public Recipe1M dataset shows that the subspace learned via the proposed method outperforms the current state-of-the-arts (SoTA) in food retrieval by a large margin, obtaining recall@1 of 0.64. Furthermore, in order to demonstrate the representational power of the learned subspace, we propose a generative food image synthesis model conditioned on the embeddings of recipes. Synthesized images can effectively reproduce the visual appearance of paired samples, achieving R@1 of 0.68 in the image-to-recipe retrieval experiment, thus effectively capturing the semantics of the textual recipe.