 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review on Recent Methods and Challenges of Video Description
Paper and Code

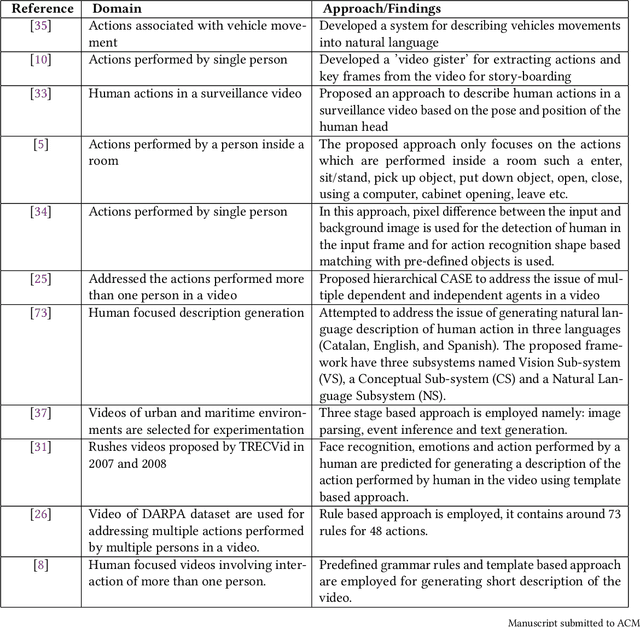
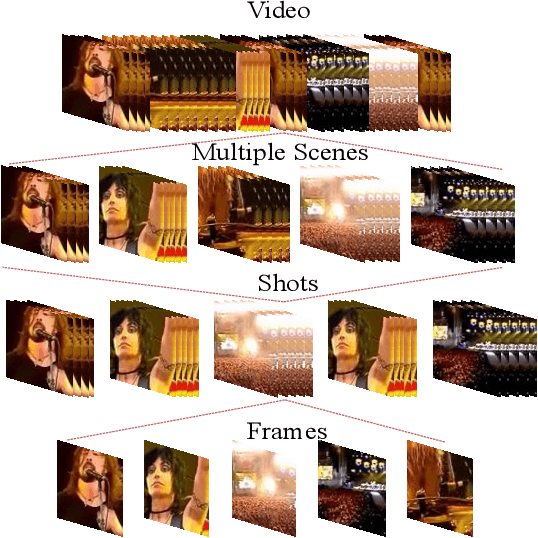
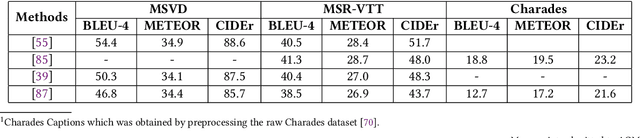
Video description involves the generation of the natural language description of actions, events, and objects in the video. There are various applications of video description by filling the gap between languages and vision for visually impaired people, generating automatic title suggestion based on content, browsing of the video based on the content and video-guided machine translation [86] etc.In the past decade, several works had been done in this field in terms of approaches/methods for video description, evaluation metrics,and datasets. For analyzing the progress in the video description task, a comprehensive survey is needed that covers all the phases of video description approaches with a special focus on recent deep learning approaches. In this work, we report a comprehensive survey on the phases of video description approaches, the dataset for video description, evaluation metrics, open competitions for motivating the research on the video description, open challenges in this field, and future research directions. In this survey, we cover the state-of-the-art approaches proposed for each and every dataset with their pros and cons. For the growth of this research domain,the availability of numerous benchmark dataset is a basic need. Further, we categorize all the dataset into two classes: open domain dataset and domain-specific dataset. From our survey, we observe that the work in this field is in fast-paced development since the task of video description falls in the intersection of computer vision and natural language processing. But still, the work in the video description is far from saturation stage due to various challenges like the redundancy due to similar frames which affect the quality of visual features, the availability of dataset containing more diverse content and availability of an effective evaluation metric.