 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Human Pose and Shape Estimation Using Learnable Volumetric Aggregation
Paper and Code
Nov 26, 2020
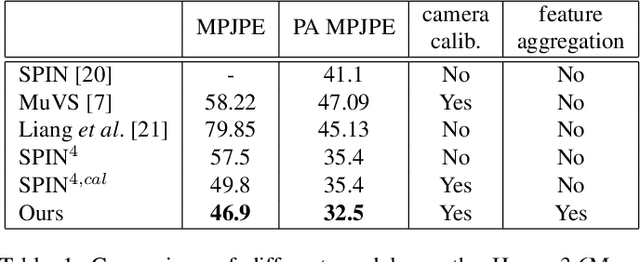
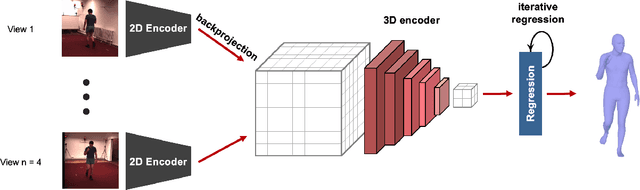
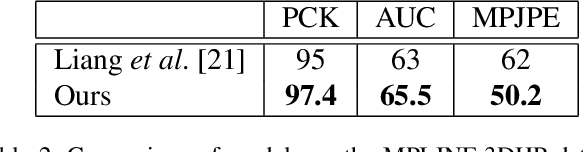
Human pose and shape estimation from RGB images is a highly sought after alternative to marker-based motion capture, which is laborious, requires expensive equipment, and constrains capture to laboratory environments. Monocular vision-based algorithms, however, still suffer from rotational ambiguities and are not ready for translation in healthcare applications, where high accuracy is paramount. While fusion of data from multiple viewpoints could overcome these challenges, current algorithms require further improvement to obtain clinically acceptable accuracies. In this paper, we propose a learnable volumetric aggregation approach to reconstruct 3D human body pose and shape from calibrated multi-view images. We use a parametric representation of the human body, which makes our approach directly applicable to medical applications. Compared to previous approaches, our framework shows higher accuracy and greater promise for real-time prediction, given its cost efficiency.