 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenmark's Participation in the Search Engine TREC COVID-19 Challenge: Lessons Learned about Searching for Precise Biomedical Scientific Information on COVID-19
Paper and Code

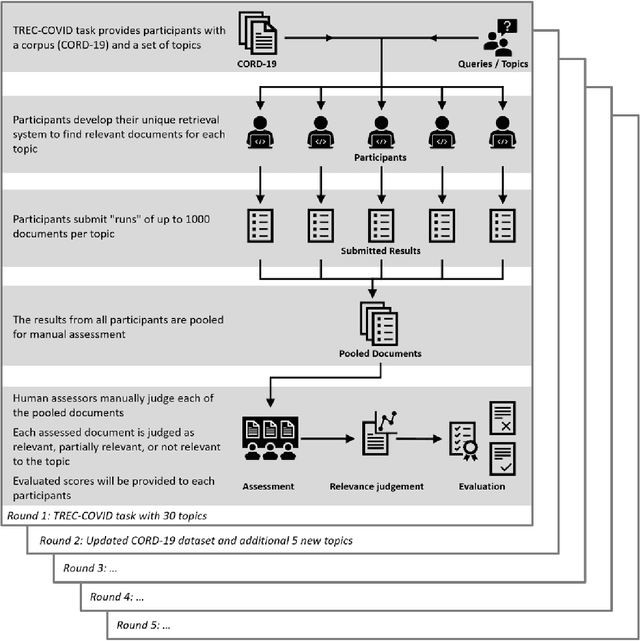
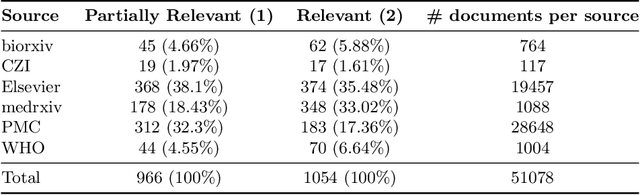
This report describes the participation of two Danish universities, University of Copenhagen and Aalborg University, in the international search engine competition on COVID-19 (the 2020 TREC-COVID Challenge) organised by the U.S. National Institute of Standards and Technology (NIST) and its Text Retrieval Conference (TREC) division. The aim of the competition was to find the best search engine strategy for retrieving precise biomedical scientific information on COVID-19 from the largest, at that point in time, dataset of curated scientific literature on COVID-19 -- the COVID-19 Open Research Dataset (CORD-19). CORD-19 was the result of a call to action to the tech community by the U.S. White House in March 2020, and was shortly thereafter posted on Kaggle as an AI competition by the Allen Institute for AI, the Chan Zuckerberg Initiative, Georgetown University's Center for Security and Emerging Technology, Microsoft, and the National Library of Medicine at the US National Institutes of Health. CORD-19 contained over 200,000 scholarly articles (of which more than 100,000 were with full text) about COVID-19, SARS-CoV-2, and related coronaviruses, gathered from curated biomedical sources. The TREC-COVID challenge asked for the best way to (a) retrieve accurate and precise scientific information, in response to some queries formulated by biomedical experts, and (b) rank this information decreasingly by its relevance to the query. In this document, we describe the TREC-COVID competition setup, our participation to it, and our resulting reflections and lessons learned about the state-of-art technology when faced with the acute task of retrieving precise scientific information from a rapidly growing corpus of literature, in response to highly specialised queries, in the middle of a pandemic.