 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Decoupled Spatial-Temporal Contrast for Self-supervised Video Representation Learning
Paper and Code
Nov 23, 2020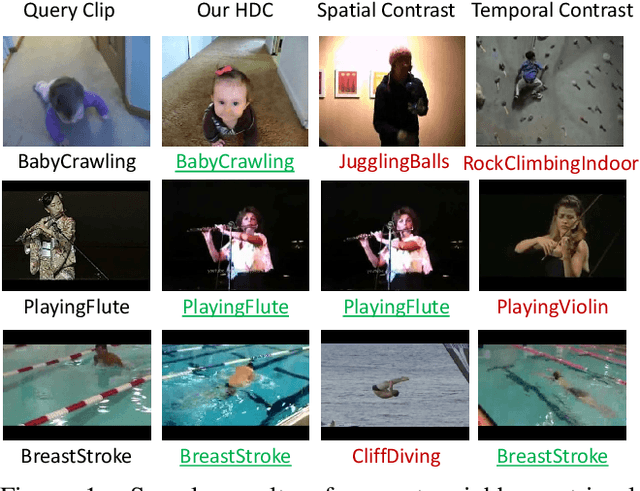
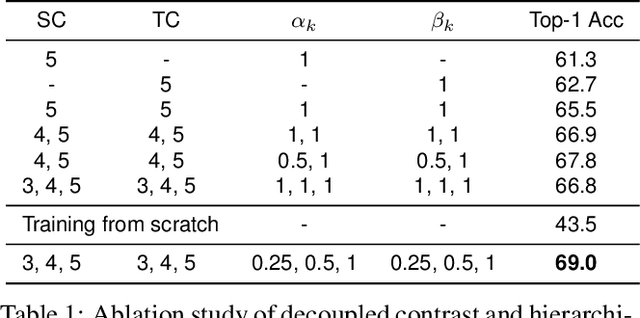
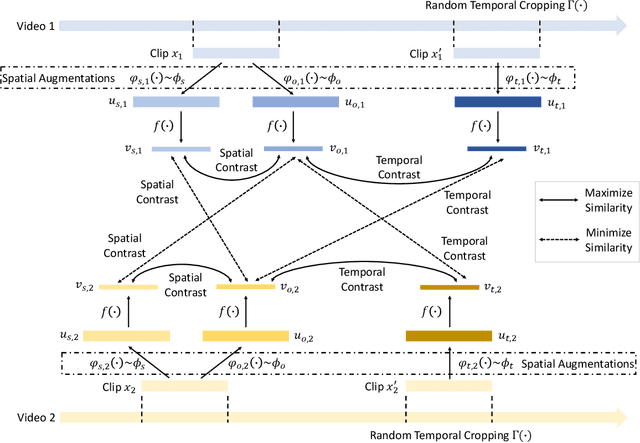
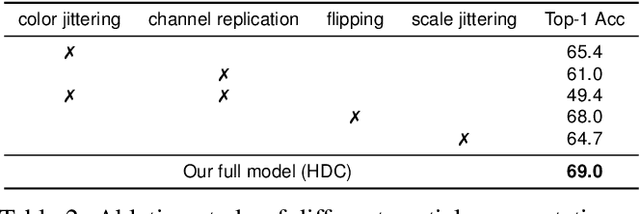
We present a novel way for self-supervised video representation learning by: (a) decoupling the learning objective into two contrastive subtasks respectively emphasizing spatial and temporal features, and (b) performing it hierarchically to encourage multi-scale understanding. Motivated by their effectiveness in supervised learning, we first introduce spatial-temporal feature learning decoupling and hierarchical learning to the context of unsupervised video learning. In particular, our method directs the network to separately capture spatial and temporal features on the basis of contrastive learning via manipulating augmentations as regularization, and further solve such proxy tasks hierarchically by optimizing towards a compound contrastive loss. Experiments show that our proposed Hierarchically Decoupled Spatial-Temporal Contrast (HDC) achieves substantial gains over directly learning spatial-temporal features as a whole and significantly outperforms other state-of-the-art unsupervised methods on downstream action recognition benchmarks on UCF101 and HMDB51. We will release our code and pretrained weights.