 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Contention Window Design using Deep Q-learning
Paper and Code
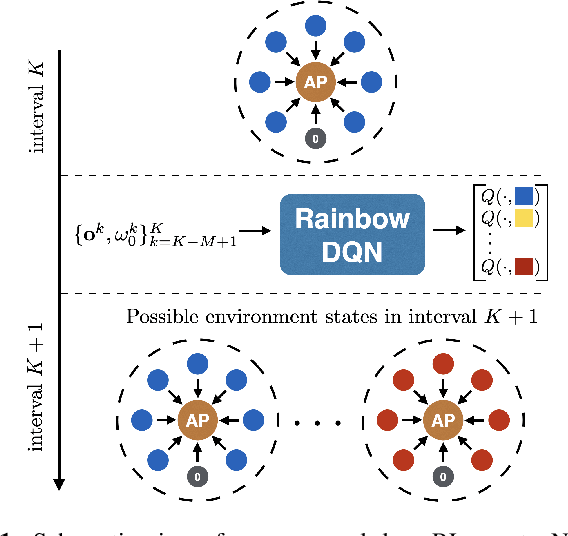
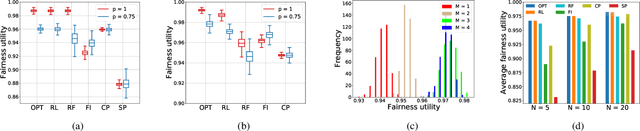
We study the problem of adaptive contention window (CW) design for random-access wireless networks. More precisely, our goal is to design an intelligent node that can dynamically adapt its minimum CW (MCW) parameter to maximize a network-level utility knowing neither the MCWs of other nodes nor how these change over time. To achieve this goal, we adopt a reinforcement learning (RL) framework where we circumvent the lack of system knowledge with local channel observations and we reward actions that lead to high utilities. To efficiently learn these preferred actions, we follow a deep Q-learning approach, where the Q-value function is parametrized using a multi-layer perception. In particular, we implement a rainbow agent, which incorporates several empirical improvements over the basic deep Q-network. Numerical experiments based on the NS3 simulator reveal that the proposed RL agent performs close to optimal and markedly improves upon existing learning and non-learning based alternatives.