 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Sensitive Machine Learning Classification for Mass Tuberculosis Verbal Screening
Paper and Code
Nov 14, 2020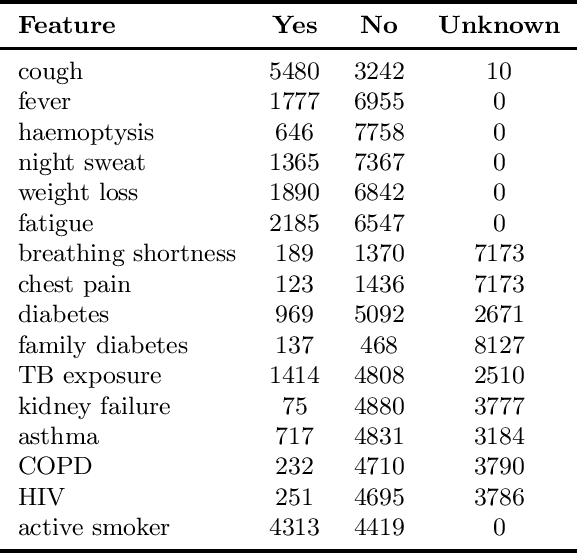
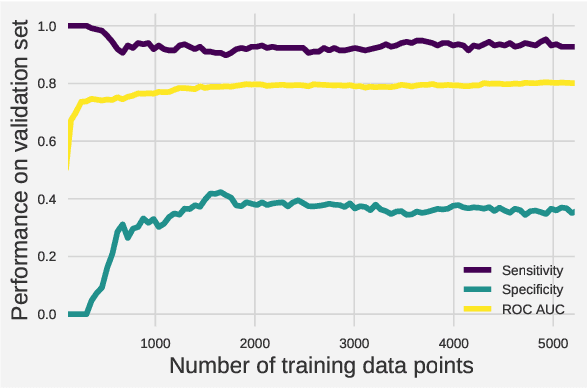
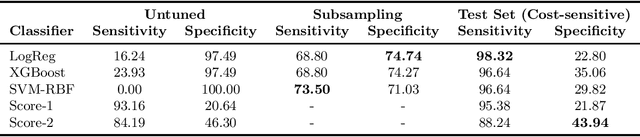
Score-based algorithms for tuberculosis (TB) verbal screening perform poorly, causing misclassification that leads to missed cases and unnecessary costly laboratory tests for false positives. We compared score-based classification defined by clinicians to machine learning classification such as SVM-RBF, logistic regression, and XGBoost. We restricted our analyses to data from adults, the population most affected by TB, and investigated the difference between untuned and unweighted classifiers to the cost-sensitive ones. Predictions were compared with the corresponding GeneXpert MTB/Rif results. After adjusting the weight of the positive class to 40 for XGBoost, we achieved 96.64% sensitivity and 35.06% specificity. As such, the sensitivity of our identifier increased by 1.26% while specificity increased by 13.19% in absolute value compared to the traditional score-based method defined by our clinicians. Our approach further demonstrated that only 2000 data points were sufficient to enable the model to converge. The results indicate that even with limited data we can actually devise a better method to identify TB suspects from verbal screening.