 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis for Sinhala Language using Deep Learning Techniques
Paper and Code
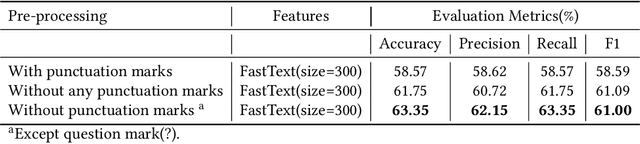

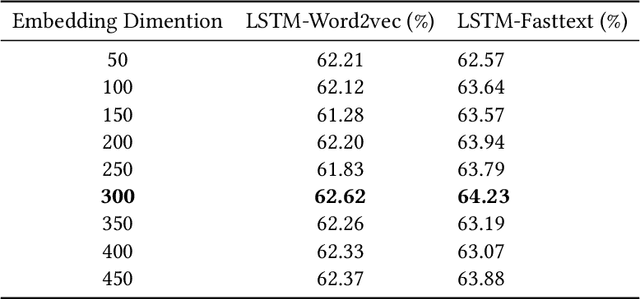
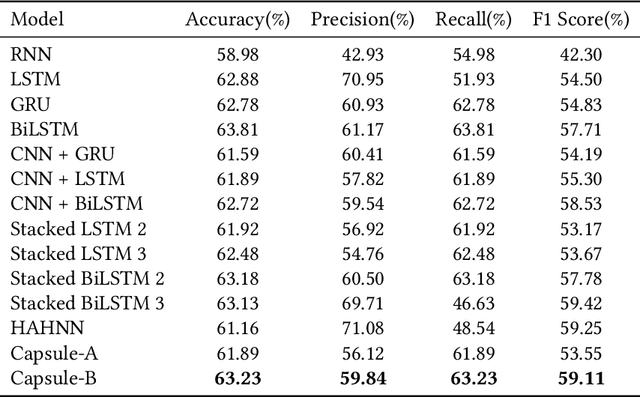
Due to the high impact of the fast-evolving fields of machine learning and deep learning, Natural Language Processing (NLP) tasks have further obtained comprehensive performances for highly resourced languages such as English and Chinese. However Sinhala, which is an under-resourced language with a rich morphology, has not experienced these advancements. For sentiment analysis, there exists only two previous research with deep learning approaches, which focused only on document-level sentiment analysis for the binary case. They experimented with only three types of deep learning models. In contrast, this paper presents a much comprehensive study on the use of standard sequence models such as RNN, LSTM, Bi-LSTM, as well as more recent state-of-the-art models such as hierarchical attention hybrid neural networks, and capsule networks. Classification is done at document-level but with more granularity by considering POSITIVE, NEGATIVE, NEUTRAL, and CONFLICT classes. A data set of 15059 Sinhala news comments, annotated with these four classes and a corpus consists of 9.48 million tokens are publicly released. This is the largest sentiment annotated data set for Sinhala so far.