 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data -- A Privacy Mirage
Paper and Code
Dec 11, 2020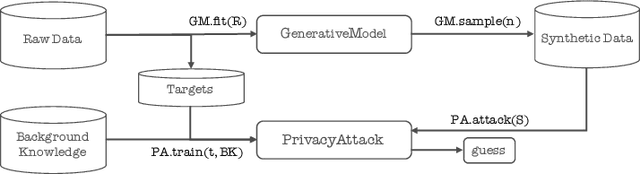
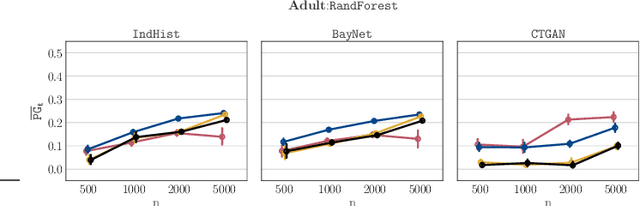
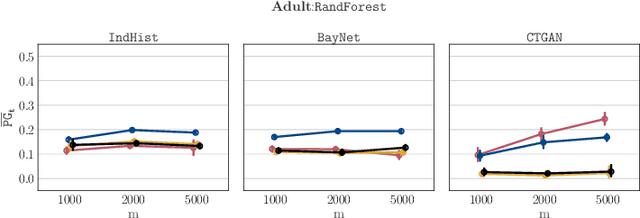
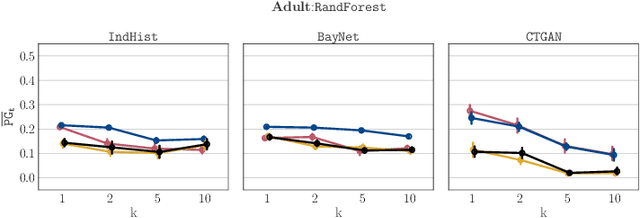
Synthetic datasets drawn from generative models have been advertised as a silver-bullet solution to privacy-preserving data publishing. In this work, we show through an extensive privacy evaluation that such claims do not match reality. First, synthetic data does not prevent attribute inference. Any data characteristics preserved by a generative model for the purpose of data analysis, can simultaneously be used by an adversary to reconstruct sensitive information about individuals. Second, synthetic data does not protect against linkage attacks. We demonstrate that high-dimensional synthetic datasets preserve much more information about the raw data than the features in the model's lower-dimensional approximation. This rich information can be exploited by an adversary even when models are trained under differential privacy. Moreover, we observe that some target records receive substantially less protection than others and that the more complex the generative model, the more difficult it is to predict which targets will remain vulnerable to inference attacks. Finally, we show why generative models are unlikely to ever become an appropriate solution to the problem of privacy-preserving data publishing.