 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatchwise Probabilistic Incremental Data Cleaning
Paper and Code
Nov 09, 2020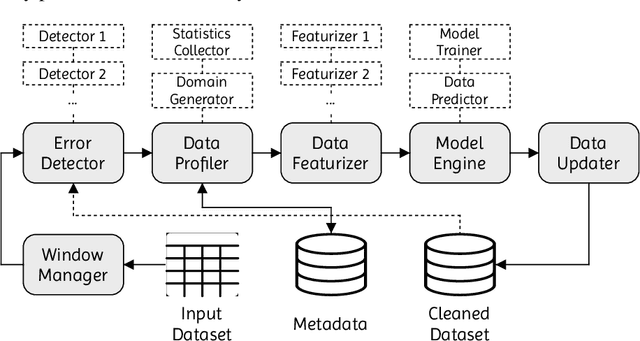
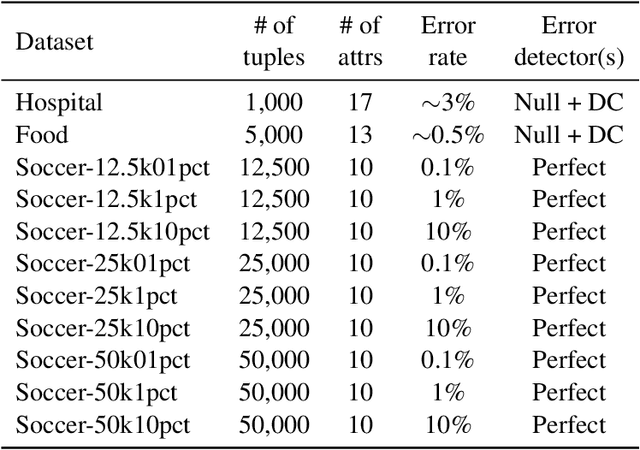
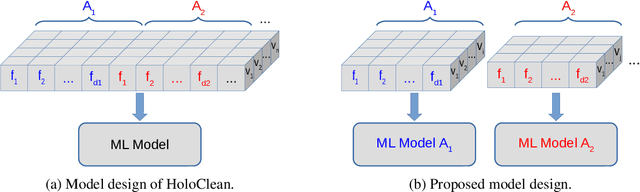
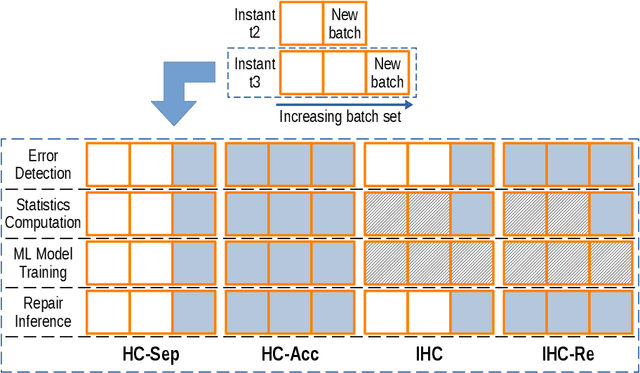
Lack of data and data quality issues are among the main bottlenecks that prevent further artificial intelligence adoption within many organizations, pushing data scientists to spend most of their time cleaning data before being able to answer analytical questions. Hence, there is a need for more effective and efficient data cleaning solutions, which, not surprisingly, is rife with theoretical and engineering problems. This report addresses the problem of performing holistic data cleaning incrementally, given a fixed rule set and an evolving categorical relational dataset acquired in sequential batches. To the best of our knowledge, our contributions compose the first incremental framework that cleans data (i) independently of user interventions, (ii) without requiring knowledge about the incoming dataset, such as the number of classes per attribute, and (iii) holistically, enabling multiple error types to be repaired simultaneously, and thus avoiding conflicting repairs. Extensive experiments show that our approach outperforms the competitors with respect to repair quality, execution time, and memory consumption.