Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Available Data Parallel ML training on Mesh Networks
Paper and Code
Nov 06, 2020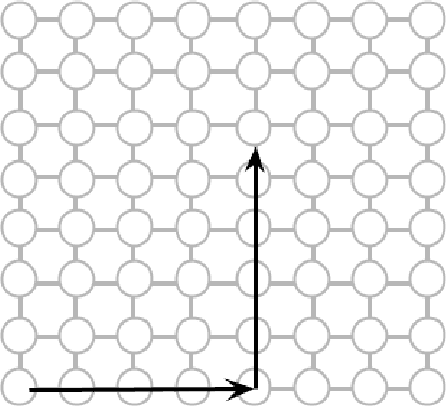

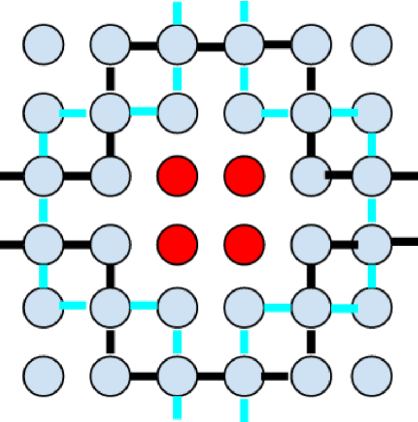
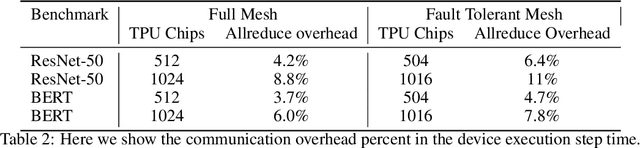
Data parallel ML models can take several days or weeks to train on several accelerators. The long duration of training relies on the cluster of resources to be available for the job to keep running for the entire duration. On a mesh network this is challenging because failures will create holes in the mesh. Packets must be routed around the failed chips for full connectivity. In this paper, we present techniques to route gradient summation allreduce traffic around failed chips on 2-D meshes. We evaluate performance of our fault tolerant allreduce techniques via the MLPerf-v0.7 ResNet-50 and BERT benchmarks. Performance results show minimal impact to training throughput on 512 and 1024 TPU-v3 chips.
View paper on