 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Bias In Dutch Word Embeddings
Paper and Code

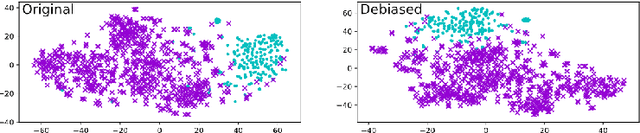
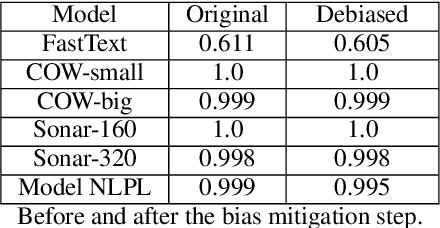

Recent research in Natural Language Processing has revealed that word embeddings can encode social biases present in the training data which can affect minorities in real world applications. This paper explores the gender bias implicit in Dutch embeddings while investigating whether English language based approaches can also be used in Dutch. We implement the Word Embeddings Association Test (WEAT), Clustering and Sentence Embeddings Association Test (SEAT) methods to quantify the gender bias in Dutch word embeddings, then we proceed to reduce the bias with Hard-Debias and Sent-Debias mitigation methods and finally we evaluate the performance of the debiased embeddings in downstream tasks. The results suggest that, among others, gender bias is present in traditional and contextualized Dutch word embeddings. We highlight how techniques used to measure and reduce bias created for English can be used in Dutch embeddings by adequately translating the data and taking into account the unique characteristics of the language. Furthermore, we analyze the effect of the debiasing techniques on downstream tasks which show a negligible impact on traditional embeddings and a 2% decrease in performance in contextualized embeddings. Finally, we release the translated Dutch datasets to the public along with the traditional embeddings with mitigated bias.