 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Domain Dialogue Generation Based on Pre-trained Language Models
Paper and Code
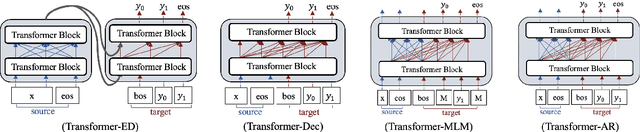

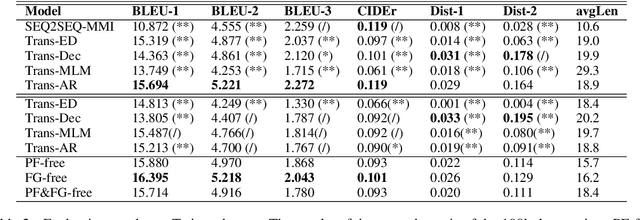
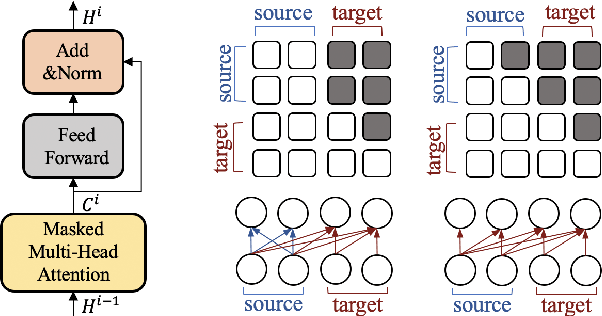
Pre-trained language models have been successfully used in response generation for open-domain dialogue. Four main frameworks have been proposed: (1) Transformer-ED using Transformer encoder and decoder separately for source and target sentences; (2) Transformer-Dec using Transformer decoder for both source and target sentences; (3) Transformer-MLM using Transformer decoder that applies bi-directional attention on the source side and left-to-right attention on the target side with masked language model objective; and (4) Transformer-AR that uses auto-regressive objective instead. In this study, we compare these frameworks on 3 datasets, and our comparison reveals that the best framework uses bidirectional attention on the source side and does not separate encoder and decoder. We also examine model discrepancy, and our experiments confirm that the performance of a model is directly impacted by the underlying discrepancies. We then propose two correction methods to reduce the discrepancies, and both improve the model performance. These results show that discrepancies is an important factor to consider when we use a pre-trained model, and a reduction in discrepancies can lead to improved performance.