 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
Paper and Code
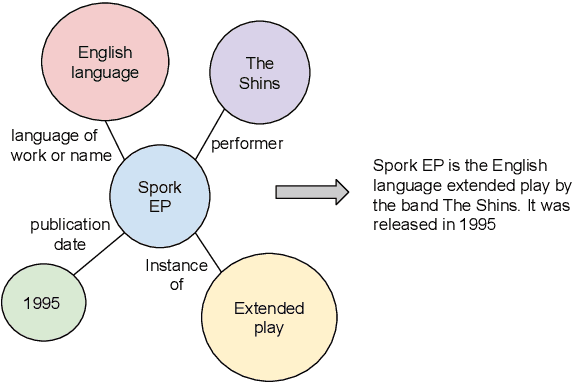

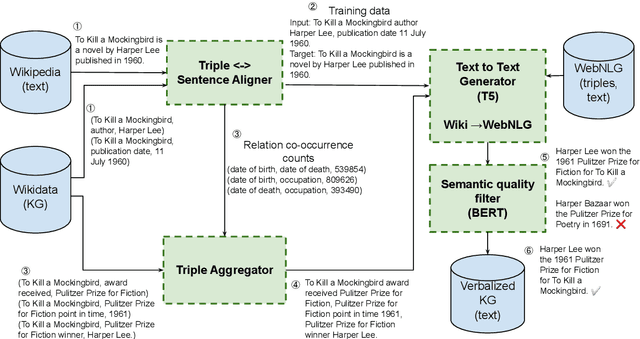
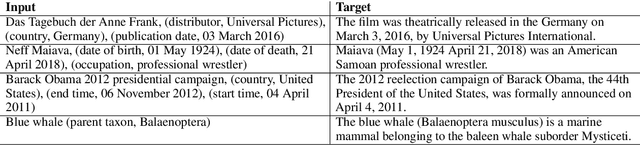
Generating natural sentences from Knowledge Graph (KG) triples, known as Data-To-Text Generation, is a task with many datasets for which numerous complex systems have been developed. However, no prior work has attempted to perform this generation at scale by converting an entire KG into natural text. In this paper, we verbalize the entire Wikidata KG, and create a KG-Text aligned corpus in the training process. We discuss the challenges in verbalizing an entire KG versus verbalizing smaller datasets. We further show that verbalizing an entire KG can be used to integrate structured and natural language data. In contrast to the many architectures that have been developed to integrate the structural differences between these two sources, our approach converts the KG into the same format as natural text allowing it to be seamlessly plugged into existing natural language systems. We evaluate this approach by augmenting the retrieval corpus in REALM and showing improvements, both on the LAMA knowledge probe and open domain QA.