 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateBERT: Retraining BERT for Abusive Language Detection in English
Paper and Code
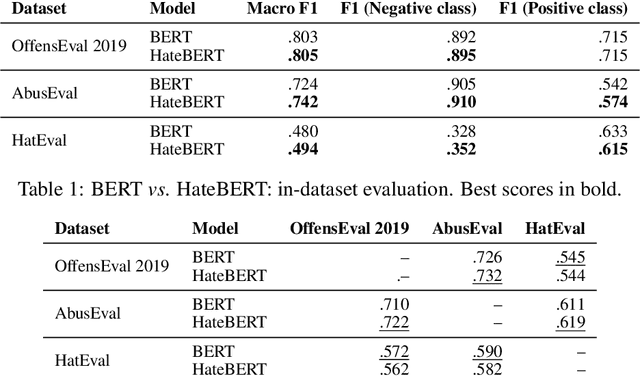

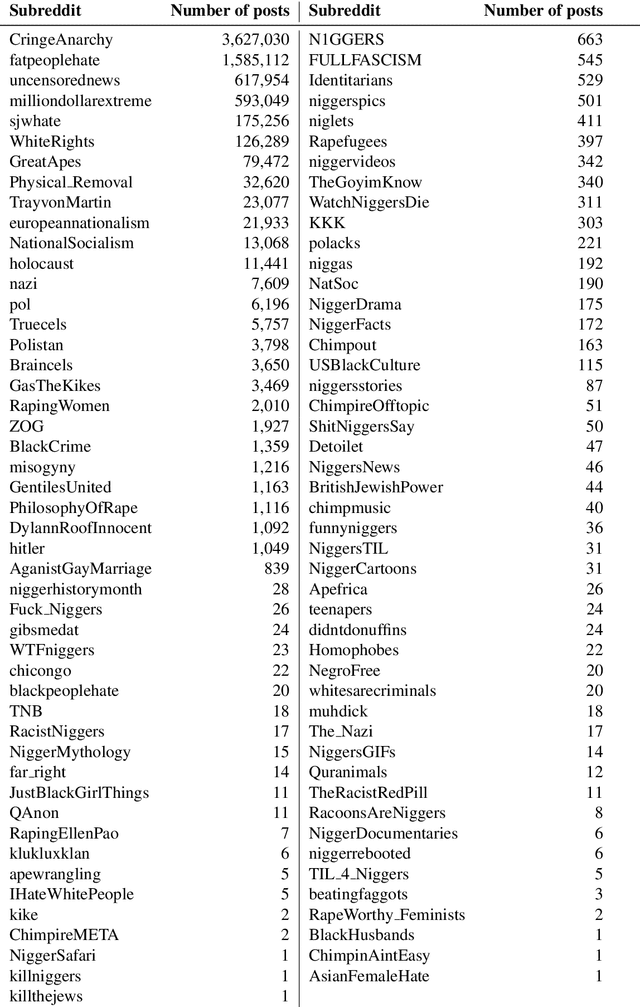
In this paper, we introduce HateBERT, a re-trained BERT model for abusive language detection in English. The model was trained on RAL-E, a large-scale dataset of Reddit comments in English from communities banned for being offensive, abusive, or hateful that we have collected and made available to the public. We present the results of a detailed comparison between a general pre-trained language model and the abuse-inclined version obtained by retraining with posts from the banned communities on three English datasets for offensive, abusive language and hate speech detection tasks. In all datasets, HateBERT outperforms the corresponding general BERT model. We also discuss a battery of experiments comparing the portability of the general pre-trained language model and its corresponding abusive language-inclined counterpart across the datasets, indicating that portability is affected by compatibility of the annotated phenomena.