 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Language Tools for Fifteen EU-official Under-resourced Languages
Paper and Code

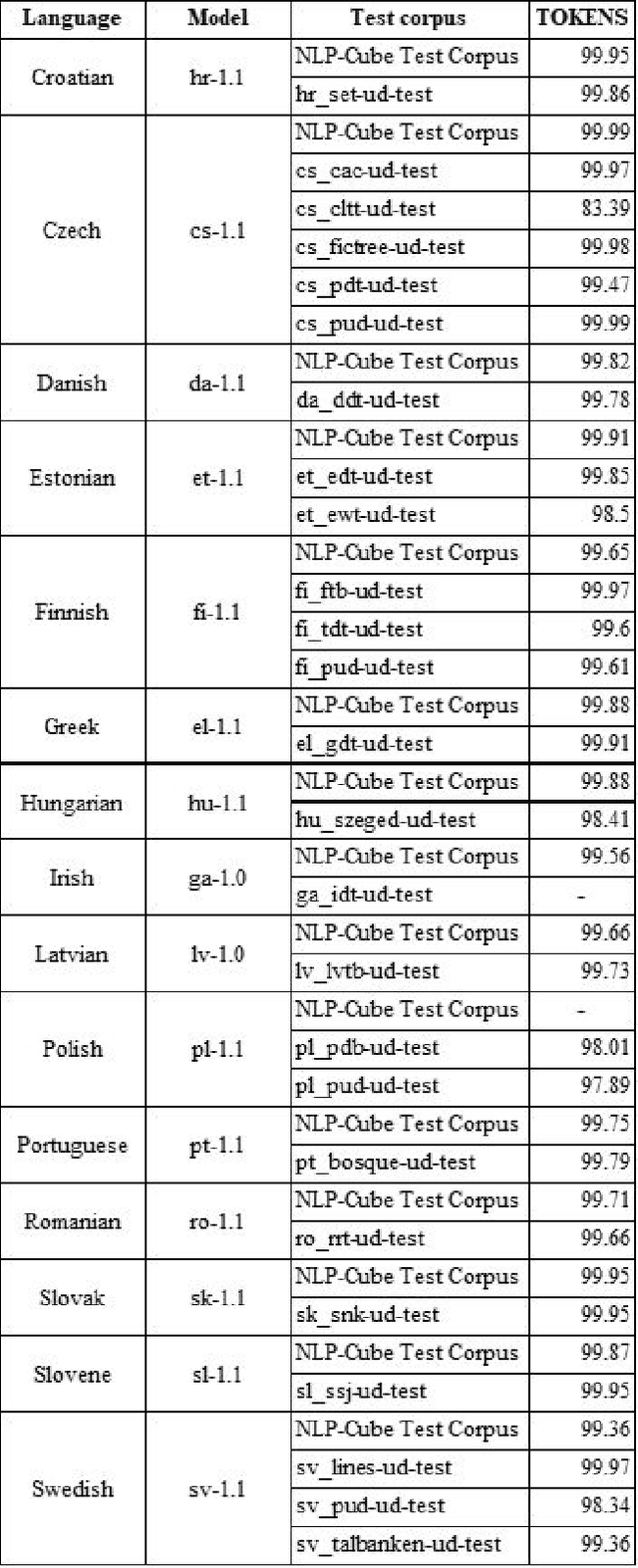
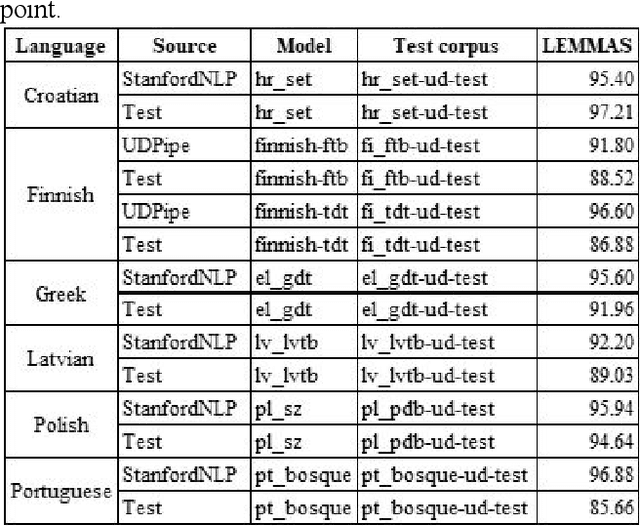
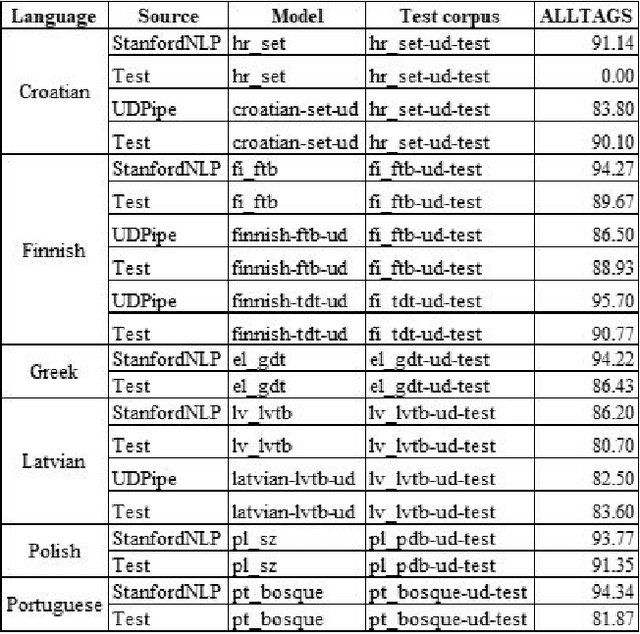
This article presents the results of the evaluation campaign of language tools available for fifteen EU-official under-resourced languages. The evaluation was conducted within the MSC ITN CLEOPATRA action that aims at building the cross-lingual event-centric knowledge processing on top of the application of linguistic processing chains (LPCs) for at least 24 EU-official languages. In this campaign, we concentrated on three existing NLP platforms (Stanford CoreNLP, NLP Cube, UDPipe) that all provide models for under-resourced languages and in this first run we covered 15 under-resourced languages for which the models were available. We present the design of the evaluation campaign and present the results as well as discuss them. We considered the difference between reported and our tested results within a single percentage point as being within the limits of acceptable tolerance and thus consider this result as reproducible. However, for a number of languages, the results are below what was reported in the literature, and in some cases, our testing results are even better than the ones reported previously. Particularly problematic was the evaluation of NERC systems. One of the reasons is the absence of universally or cross-lingually applicable named entities classification scheme that would serve the NERC task in different languages analogous to the Universal Dependency scheme in parsing task. To build such a scheme has become one of our the future research directions.